 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsembling over Classifiers: a Bias-Variance Perspective
Paper and Code
Jun 21, 2022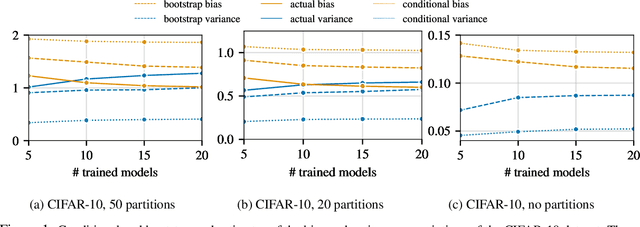
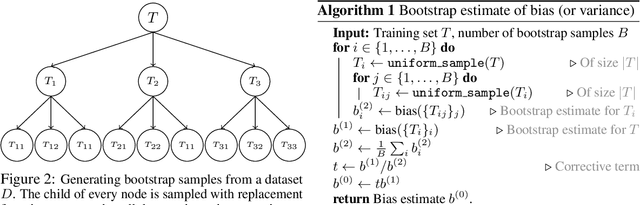
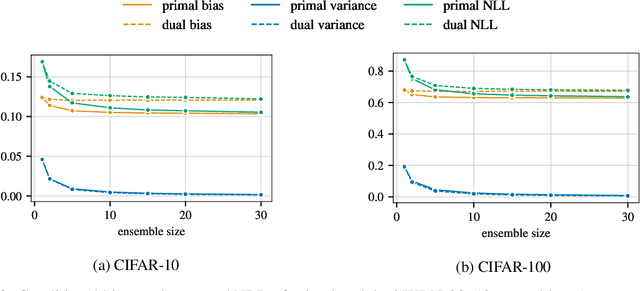
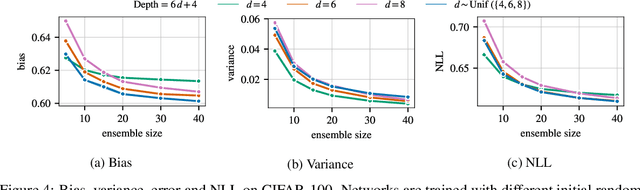
Ensembles are a straightforward, remarkably effective method for improving the accuracy,calibration, and robustness of models on classification tasks; yet, the reasons that underlie their success remain an active area of research. We build upon the extension to the bias-variance decomposition by Pfau (2013) in order to gain crucial insights into the behavior of ensembles of classifiers. Introducing a dual reparameterization of the bias-variance tradeoff, we first derive generalized laws of total expectation and variance for nonsymmetric losses typical of classification tasks. Comparing conditional and bootstrap bias/variance estimates, we then show that conditional estimates necessarily incur an irreducible error. Next, we show that ensembling in dual space reduces the variance and leaves the bias unchanged, whereas standard ensembling can arbitrarily affect the bias. Empirically, standard ensembling reducesthe bias, leading us to hypothesize that ensembles of classifiers may perform well in part because of this unexpected reduction.We conclude by an empirical analysis of recent deep learning methods that ensemble over hyperparameters, revealing that these techniques indeed favor bias reduction. This suggests that, contrary to classical wisdom, targeting bias reduction may be a promising direction for classifier ensembles.