 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnrollment-less training for personalized voice activity detection
Paper and Code
Jun 23, 2021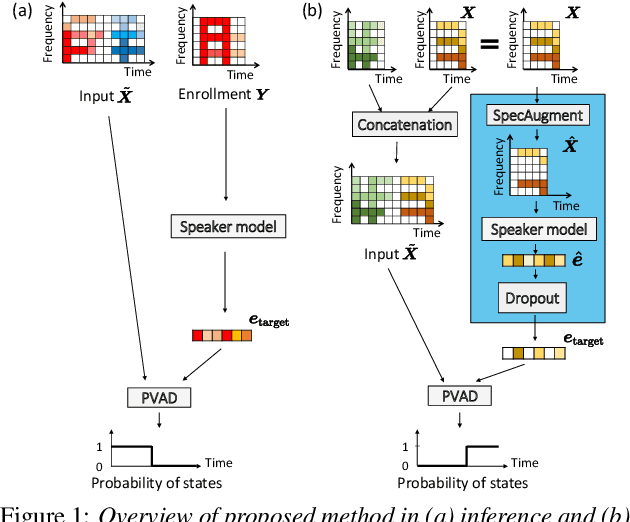
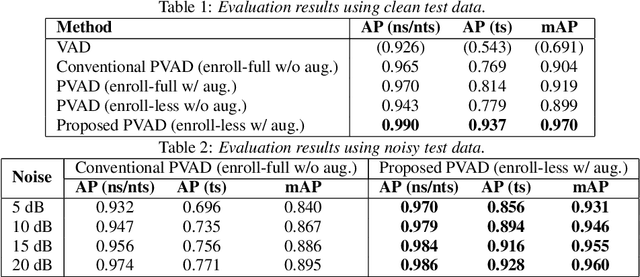
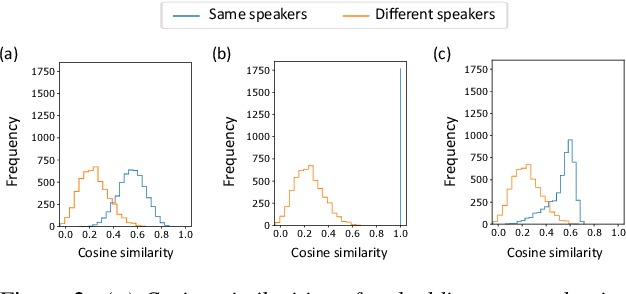
We present a novel personalized voice activity detection (PVAD) learning method that does not require enrollment data during training. PVAD is a task to detect the speech segments of a specific target speaker at the frame level using enrollment speech of the target speaker. Since PVAD must learn speakers' speech variations to clarify the boundary between speakers, studies on PVAD used large-scale datasets that contain many utterances for each speaker. However, the datasets to train a PVAD model are often limited because substantial cost is needed to prepare such a dataset. In addition, we cannot utilize the datasets used to train the standard VAD because they often lack speaker labels. To solve these problems, our key idea is to use one utterance as both a kind of enrollment speech and an input to the PVAD during training, which enables PVAD training without enrollment speech. In our proposed method, called enrollment-less training, we augment one utterance so as to create variability between the input and the enrollment speech while keeping the speaker identity, which avoids the mismatch between training and inference. Our experimental results demonstrate the efficacy of the method.