 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriched Long-term Recurrent Convolutional Network for Facial Micro-Expression Recognition
Paper and Code



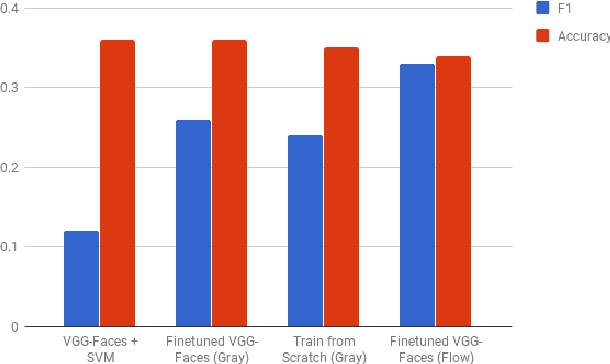
Facial micro-expression (ME) recognition has posed a huge challenge to researchers for its subtlety in motion and limited databases. Recently, handcrafted techniques have achieved superior performance in micro-expression recognition but at the cost of domain specificity and cumbersome parametric tunings. In this paper, we propose an Enriched Long-term Recurrent Convolutional Network (ELRCN) that first encodes each micro-expression frame into a feature vector through CNN module(s), then predicts the micro-expression by passing the feature vector through a Long Short-term Memory (LSTM) module. The framework contains two different network variants: (1) Channel-wise stacking of input data for spatial enrichment, (2) Feature-wise stacking of features for temporal enrichment. We demonstrate that the proposed approach is able to achieve reasonably good performance, without data augmentation. In addition, we also present ablation studies conducted on the framework and visualizations of what CNN "sees" when predicting the micro-expression classes.