 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Table Representations with LLM-powered Synthetic Data Generation
Paper and Code
Nov 04, 2024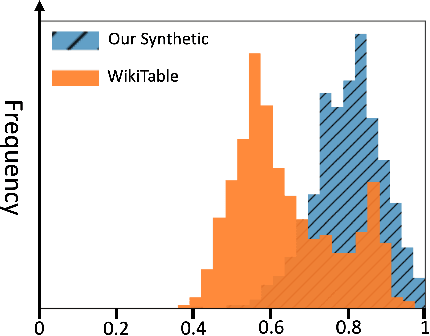



In the era of data-driven decision-making, accurate table-level representations and efficient table recommendation systems are becoming increasingly crucial for improving table management, discovery, and analysis. However, existing approaches to tabular data representation often face limitations, primarily due to their focus on cell-level tasks and the lack of high-quality training data. To address these challenges, we first formulate a clear definition of table similarity in the context of data transformation activities within data-driven enterprises. This definition serves as the foundation for synthetic data generation, which require a well-defined data generation process. Building on this, we propose a novel synthetic data generation pipeline that harnesses the code generation and data manipulation capabilities of Large Language Models (LLMs) to create a large-scale synthetic dataset tailored for table-level representation learning. Through manual validation and performance comparisons on the table recommendation task, we demonstrate that the synthetic data generated by our pipeline aligns with our proposed definition of table similarity and significantly enhances table representations, leading to improved recommendation performance.