 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multilingual Speech Generation and Recognition Abilities in LLMs with Constructed Code-switched Data
Paper and Code
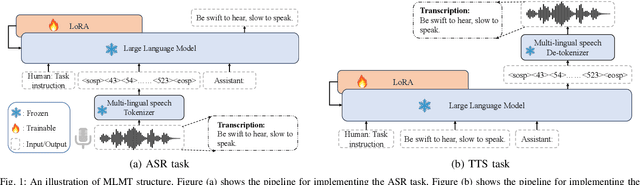
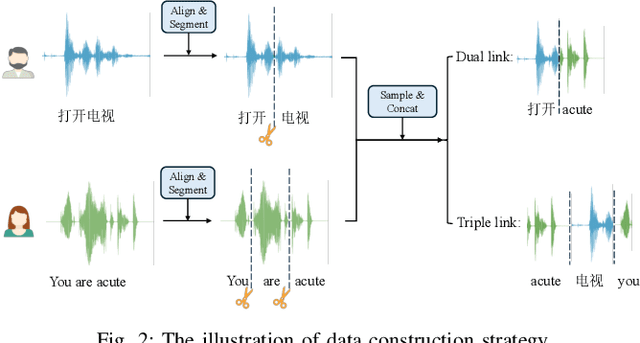
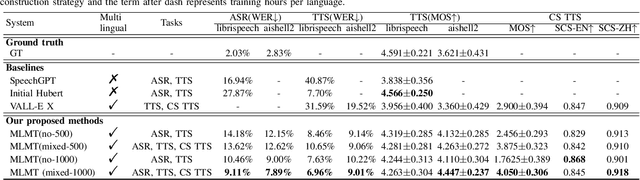
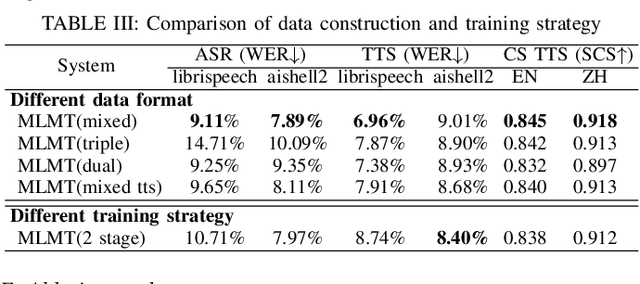
While large language models (LLMs) have been explored in the speech domain for both generation and recognition tasks, their applications are predominantly confined to the monolingual scenario, with limited exploration in multilingual and code-switched (CS) contexts. Additionally, speech generation and recognition tasks are often handled separately, such as VALL-E and Qwen-Audio. In this paper, we propose a MutltiLingual MultiTask (MLMT) model, integrating multilingual speech generation and recognition tasks within the single LLM. Furthermore, we develop an effective data construction approach that splits and concatenates words from different languages to equip LLMs with CS synthesis ability without relying on CS data. The experimental results demonstrate that our model outperforms other baselines with a comparable data scale. Furthermore, our data construction approach not only equips LLMs with CS speech synthesis capability with comparable speaker consistency and similarity to any given speaker, but also improves the performance of LLMs in multilingual speech generation and recognition tasks.