 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Handwritten Text Recognition with N-gram sequence decomposition and Multitask Learning
Paper and Code
Dec 28, 2020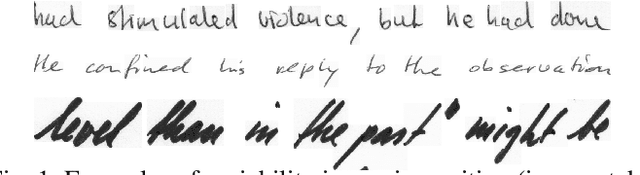
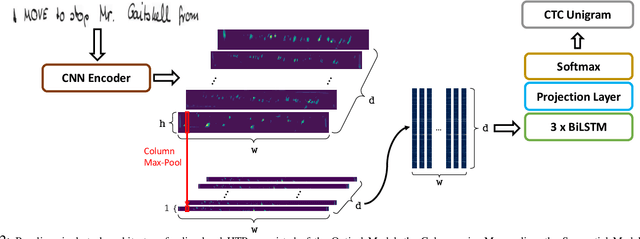
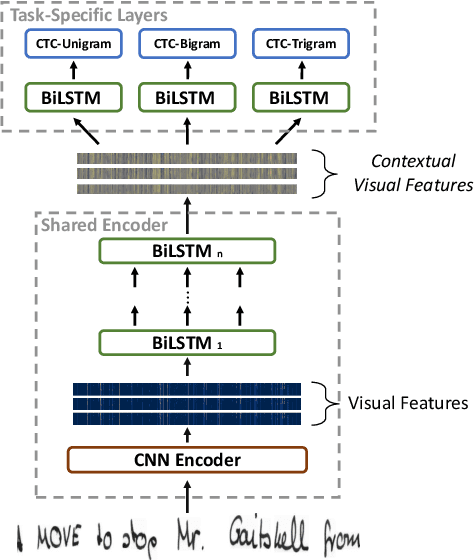
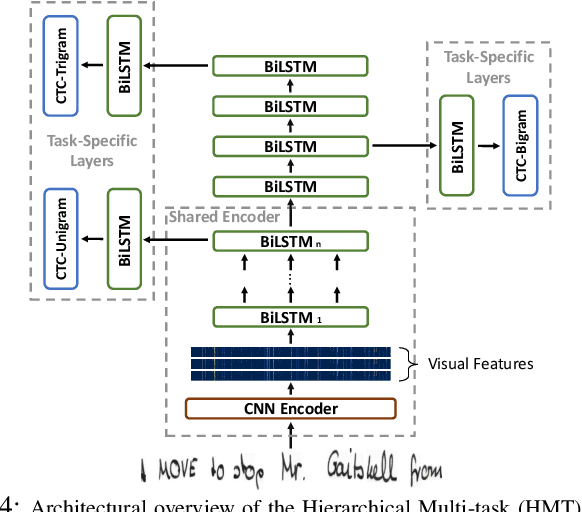
Current state-of-the-art approaches in the field of Handwritten Text Recognition are predominately single task with unigram, character level target units. In our work, we utilize a Multi-task Learning scheme, training the model to perform decompositions of the target sequence with target units of different granularity, from fine to coarse. We consider this method as a way to utilize n-gram information, implicitly, in the training process, while the final recognition is performed using only the unigram output. % in order to highlight the difference of the internal Unigram decoding of such a multi-task approach highlights the capability of the learned internal representations, imposed by the different n-grams at the training step. We select n-grams as our target units and we experiment from unigrams to fourgrams, namely subword level granularities. These multiple decompositions are learned from the network with task-specific CTC losses. Concerning network architectures, we propose two alternatives, namely the Hierarchical and the Block Multi-task. Overall, our proposed model, even though evaluated only on the unigram task, outperforms its counterpart single-task by absolute 2.52\% WER and 1.02\% CER, in the greedy decoding, without any computational overhead during inference, hinting towards successfully imposing an implicit language model.