 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Gait Video Analysis in Neurodegenerative Diseases by Knowledge Augmentation in Vision Language Model
Paper and Code
Mar 20, 2024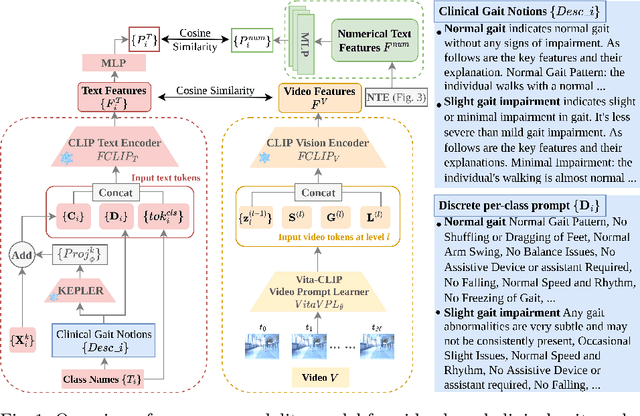
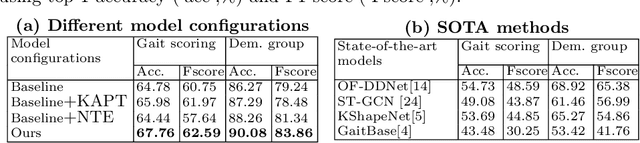
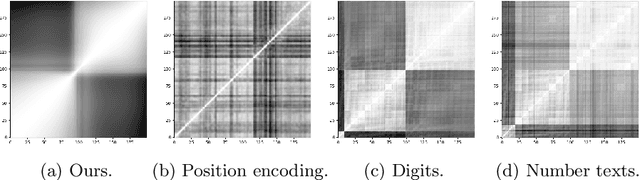
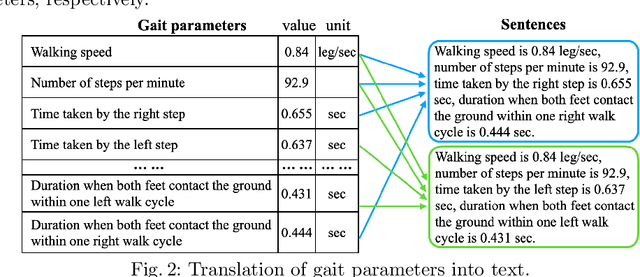
We present a knowledge augmentation strategy for assessing the diagnostic groups and gait impairment from monocular gait videos. Based on a large-scale pre-trained Vision Language Model (VLM), our model learns and improves visual, textual, and numerical representations of patient gait videos, through a collective learning across three distinct modalities: gait videos, class-specific descriptions, and numerical gait parameters. Our specific contributions are two-fold: First, we adopt a knowledge-aware prompt tuning strategy to utilize the class-specific medical description in guiding the text prompt learning. Second, we integrate the paired gait parameters in the form of numerical texts to enhance the numeracy of the textual representation. Results demonstrate that our model not only significantly outperforms state-of-the-art (SOTA) in video-based classification tasks but also adeptly decodes the learned class-specific text features into natural language descriptions using the vocabulary of quantitative gait parameters. The code and the model will be made available at our project page.