 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Explainability in Multimodal Large Language Models Using Ontological Context
Paper and Code
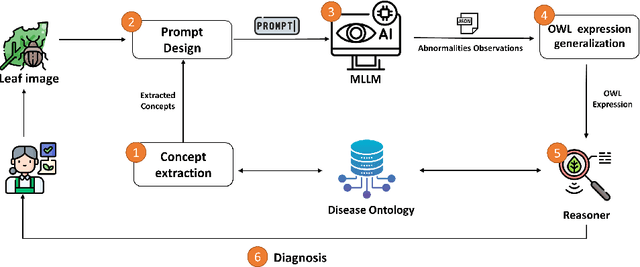



Recently, there has been a growing interest in Multimodal Large Language Models (MLLMs) due to their remarkable potential in various tasks integrating different modalities, such as image and text, as well as applications such as image captioning and visual question answering. However, such models still face challenges in accurately captioning and interpreting specific visual concepts and classes, particularly in domain-specific applications. We argue that integrating domain knowledge in the form of an ontology can significantly address these issues. In this work, as a proof of concept, we propose a new framework that combines ontology with MLLMs to classify images of plant diseases. Our method uses concepts about plant diseases from an existing disease ontology to query MLLMs and extract relevant visual concepts from images. Then, we use the reasoning capabilities of the ontology to classify the disease according to the identified concepts. Ensuring that the model accurately uses the concepts describing the disease is crucial in domain-specific applications. By employing an ontology, we can assist in verifying this alignment. Additionally, using the ontology's inference capabilities increases transparency, explainability, and trust in the decision-making process while serving as a judge by checking if the annotations of the concepts by MLLMs are aligned with those in the ontology and displaying the rationales behind their errors. Our framework offers a new direction for synergizing ontologies and MLLMs, supported by an empirical study using different well-known MLLMs.