 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnforcing Interpretability and its Statistical Impacts: Trade-offs between Accuracy and Interpretability
Paper and Code
Oct 28, 2020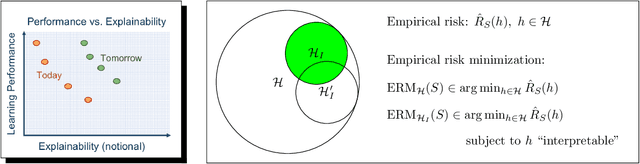
To date, there has been no formal study of the statistical cost of interpretability in machine learning. As such, the discourse around potential trade-offs is often informal and misconceptions abound. In this work, we aim to initiate a formal study of these trade-offs. A seemingly insurmountable roadblock is the lack of any agreed upon definition of interpretability. Instead, we propose a shift in perspective. Rather than attempt to define interpretability, we propose to model the \emph{act} of \emph{enforcing} interpretability. As a starting point, we focus on the setting of empirical risk minimization for binary classification, and view interpretability as a constraint placed on learning. That is, we assume we are given a subset of hypothesis that are deemed to be interpretable, possibly depending on the data distribution and other aspects of the context. We then model the act of enforcing interpretability as that of performing empirical risk minimization over the set of interpretable hypotheses. This model allows us to reason about the statistical implications of enforcing interpretability, using known results in statistical learning theory. Focusing on accuracy, we perform a case analysis, explaining why one may or may not observe a trade-off between accuracy and interpretability when the restriction to interpretable classifiers does or does not come at the cost of some excess statistical risk. We close with some worked examples and some open problems, which we hope will spur further theoretical development around the tradeoffs involved in interpretability.