 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy Trees: Regression and Classification With Structured and Mixed-Type Covariates
Paper and Code

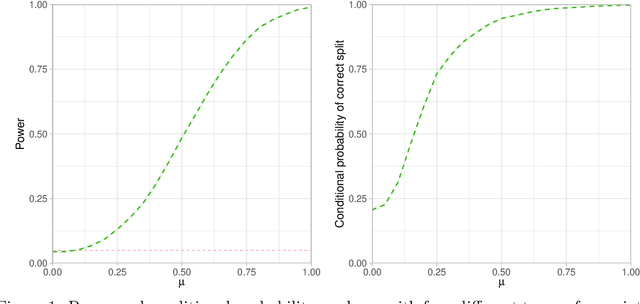
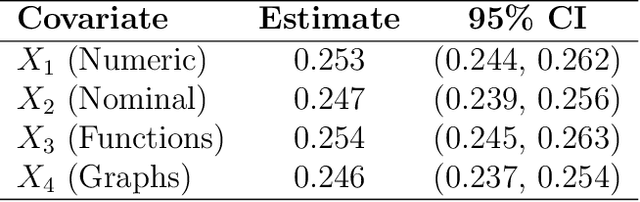

The continuous growth of data complexity requires methods and models that adequately account for non-trivial structures, as any simplification may induce loss of information. Many analytical tools have been introduced to work with complex data objects in their original form, but such tools can typically deal with single-type variables only. In this work, we propose Energy Trees as a model for regression and classification tasks where covariates are potentially both structured and of different types. Energy Trees incorporate Energy Statistics to generalize Conditional Trees, from which they inherit statistically sound foundations, interpretability, scale invariance, and lack of distributional assumptions. We focus on functions and graphs as structured covariates and we show how the model can be easily adapted to work with almost any other type of variable. Through an extensive simulation study, we highlight the good performance of our proposal in terms of variable selection and robustness to overfitting. Finally, we validate the model's predictive ability through two empirical analyses with human biological data.