 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy Propagation in Deep Convolutional Neural Networks
Paper and Code
Feb 01, 2018


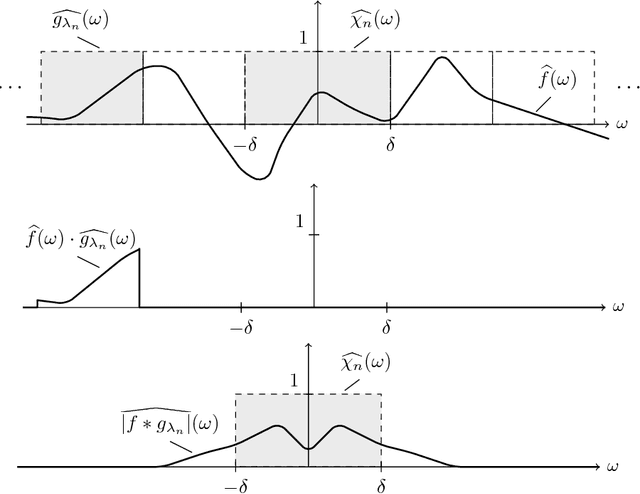
Many practical machine learning tasks employ very deep convolutional neural networks. Such large depths pose formidable computational challenges in training and operating the network. It is therefore important to understand how fast the energy contained in the propagated signals (a.k.a. feature maps) decays across layers. In addition, it is desirable that the feature extractor generated by the network be informative in the sense of the only signal mapping to the all-zeros feature vector being the zero input signal. This "trivial null-set" property can be accomplished by asking for "energy conservation" in the sense of the energy in the feature vector being proportional to that of the corresponding input signal. This paper establishes conditions for energy conservation (and thus for a trivial null-set) for a wide class of deep convolutional neural network-based feature extractors and characterizes corresponding feature map energy decay rates. Specifically, we consider general scattering networks employing the modulus non-linearity and we find that under mild analyticity and high-pass conditions on the filters (which encompass, inter alia, various constructions of Weyl-Heisenberg filters, wavelets, ridgelets, ($\alpha$)-curvelets, and shearlets) the feature map energy decays at least polynomially fast. For broad families of wavelets and Weyl-Heisenberg filters, the guaranteed decay rate is shown to be exponential. Moreover, we provide handy estimates of the number of layers needed to have at least $((1-\varepsilon)\cdot 100)\%$ of the input signal energy be contained in the feature vector.