 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-entropy competition and the effectiveness of stochastic gradient descent in machine learning
Paper and Code
Mar 05, 2018
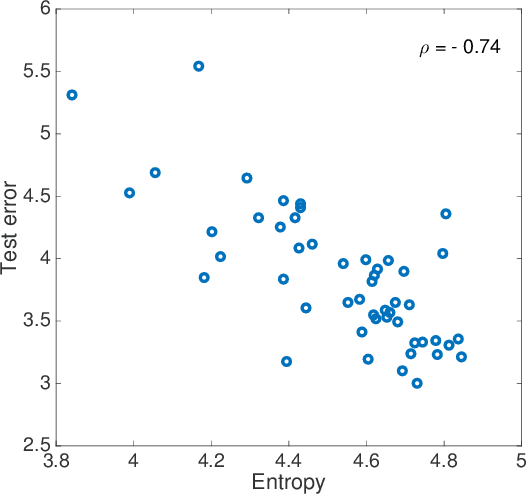


Finding parameters that minimise a loss function is at the core of many machine learning methods. The Stochastic Gradient Descent algorithm is widely used and delivers state of the art results for many problems. Nonetheless, Stochastic Gradient Descent typically cannot find the global minimum, thus its empirical effectiveness is hitherto mysterious. We derive a correspondence between parameter inference and free energy minimisation in statistical physics. The degree of undersampling plays the role of temperature. Analogous to the energy-entropy competition in statistical physics, wide but shallow minima can be optimal if the system is undersampled, as is typical in many applications. Moreover, we show that the stochasticity in the algorithm has a non-trivial correlation structure which systematically biases it towards wide minima. We illustrate our argument with two prototypical models: image classification using deep learning, and a linear neural network where we can analytically reveal the relationship between entropy and out-of-sample error.