 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end music source separation: is it possible in the waveform domain?
Paper and Code
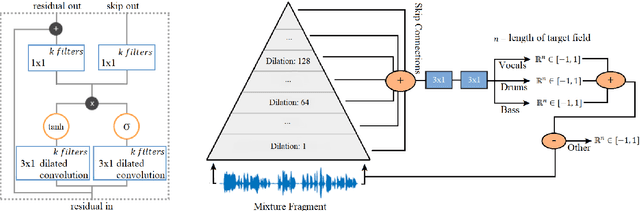

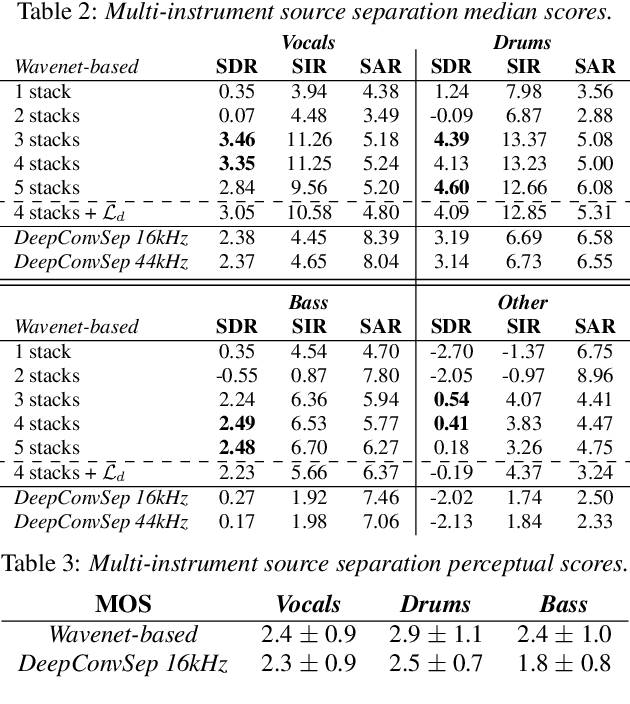
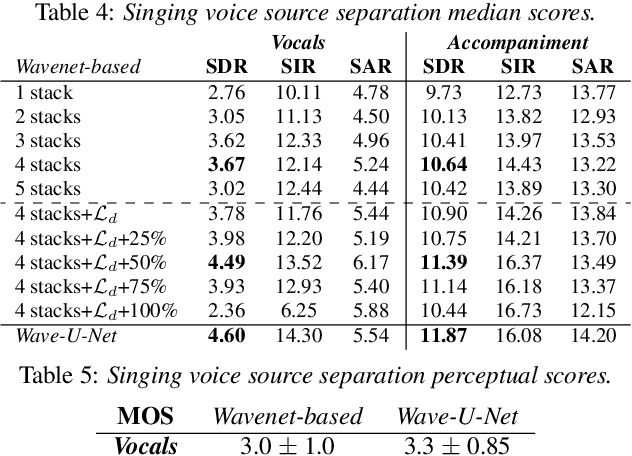
Most of the currently successful source separation techniques use the magnitude spectrogram as input, and are therefore by default omitting part of the signal: the phase. In order to avoid omitting potentially useful information, we study the viability of using end-to-end models for music source separation. By operating directly over the waveform, these models take into account all the information available in the raw audio signal, including the phase. Our results show that waveform-based models can outperform a recent spectrogram-based deep learning model. Namely, a novel Wavenet-based model we propose and Wave-U-Net can outperform DeepConvSep, a spectrogram-based deep learning model. This suggests that end-to-end learning has a great potential for the problem of music source separation.