 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-To-End Measure for Text Recognition
Paper and Code

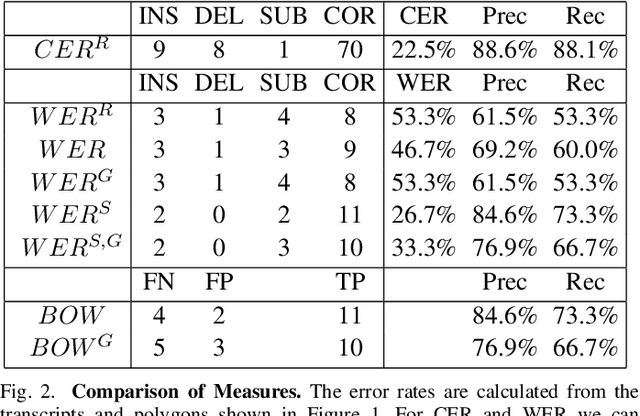
Measuring the performance of text recognition and text line detection engines is an important step to objectively compare systems and their configuration. There exist well-established measures for both tasks separately. However, there is no sophisticated evaluation scheme to measure the quality of a combined text line detection and text recognition system. The F-measure on word level is a well-known methodology, which is sometimes used in this context. Nevertheless, it does not take into account the alignment of hypothesis and ground truth text and can lead to deceptive results. Since users of automatic information retrieval pipelines in the context of text recognition are mainly interested in the end-to-end performance of a given system, there is a strong need for such a measure. Hence, we present a measure to evaluate the quality of an end-to-end text recognition system. The basis for this measure is the well established and widely used character error rate, which is limited -- in its original form -- to aligned hypothesis and ground truth texts. The proposed measure is flexible in a way that it can be configured to penalize different reading orders between the hypothesis and ground truth and can take into account the geometric position of the text lines. Additionally, it can ignore over- and under- segmentation of text lines. With these parameters it is possible to get a measure fitting best to its own needs.