 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Sparse Winograd Convolution by Native Pruning
Paper and Code
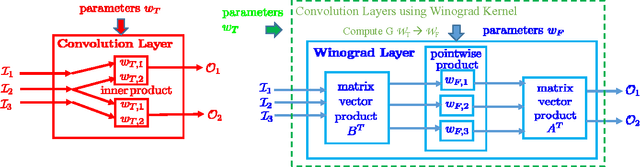
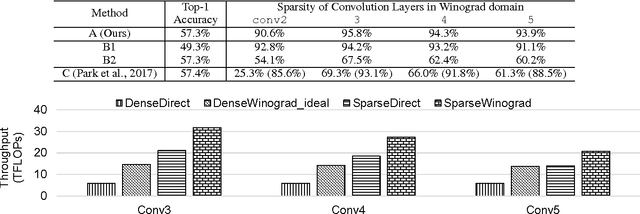
Sparse methods and the use of Winograd convolutions are two orthogonal approaches, each of which significantly accelerates convolution computations in modern CNNs. Sparse Winograd merges these two and thus has the potential to offer a combined performance benefit. Nevertheless, training convolution layers so that the resulting Winograd kernels are sparse has not hitherto been very successful. By introducing a Winograd layer in place of a standard convolution layer, we can learn and prune Winograd coefficients "natively" and obtain sparsity level beyond 90% with only 0.1% accuracy loss with AlexNet on ImageNet dataset. Furthermore, we present a sparse Winograd convolution algorithm and implementation that exploits the sparsity, achieving up to 31.7 effective TFLOP/s in 32-bit precision on a latest Intel Xeon CPU, which corresponds to a 5.4x speedup over a state-of-the-art dense convolution implementation.