 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMS: Efficient and Effective Massively Multilingual Sentence Representation Learning
Paper and Code
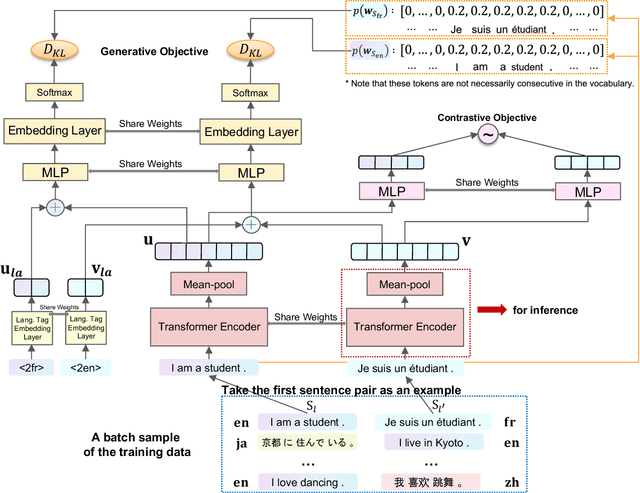
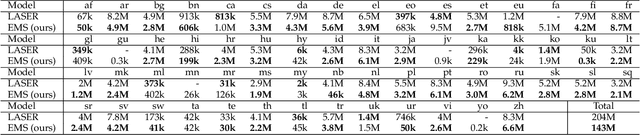


Massively multilingual sentence representation models, e.g., LASER, SBERT-distill, and LaBSE, help significantly improve cross-lingual downstream tasks. However, multiple training procedures, the use of a large amount of data, or inefficient model architectures result in heavy computation to train a new model according to our preferred languages and domains. To resolve this issue, we introduce efficient and effective massively multilingual sentence representation learning (EMS), using cross-lingual sentence reconstruction (XTR) and sentence-level contrastive learning as training objectives. Compared with related studies, the proposed model can be efficiently trained using significantly fewer parallel sentences and GPU computation resources without depending on large-scale pre-trained models. Empirical results show that the proposed model significantly yields better or comparable results with regard to bi-text mining, zero-shot cross-lingual genre classification, and sentiment classification. Ablative analyses demonstrate the effectiveness of each component of the proposed model. We release the codes for model training and the EMS pre-trained model, which supports 62 languages (https://github.com/Mao-KU/EMS).