 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical study towards understanding line search approximations for training neural networks
Paper and Code
Sep 15, 2019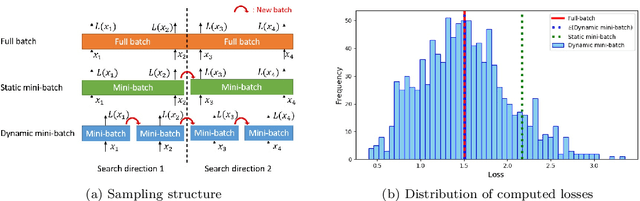

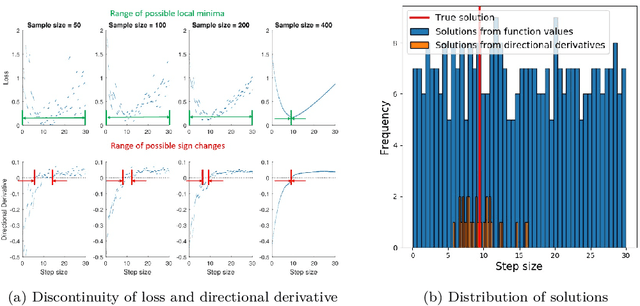
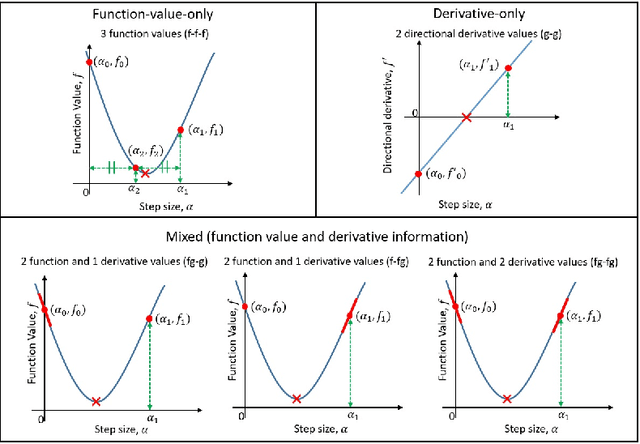
Choosing appropriate step sizes is critical for reducing the computational cost of training large-scale neural network models. Mini-batch sub-sampling (MBSS) is often employed for computational tractability. However, MBSS introduces a sampling error, that can manifest as a bias or variance in a line search. This is because MBSS can be performed statically, where the mini-batch is updated only when the search direction changes, or dynamically, where the mini-batch is updated every-time the function is evaluated. Static MBSS results in a smooth loss function along a search direction, reflecting low variance but large bias in the estimated "true" (or full batch) minimum. Conversely, dynamic MBSS results in a point-wise discontinuous function, with computable gradients using backpropagation, along a search direction, reflecting high variance but lower bias in the estimated "true" (or full batch) minimum. In this study, quadratic line search approximations are considered to study the quality of function and derivative information to construct approximations for dynamic MBSS loss functions. An empirical study is conducted where function and derivative information are enforced in various ways for the quadratic approximations. The results for various neural network problems show that being selective on what information is enforced helps to reduce the variance of predicted step sizes.