Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Study of Off-Policy Policy Evaluation for Reinforcement Learning
Paper and Code
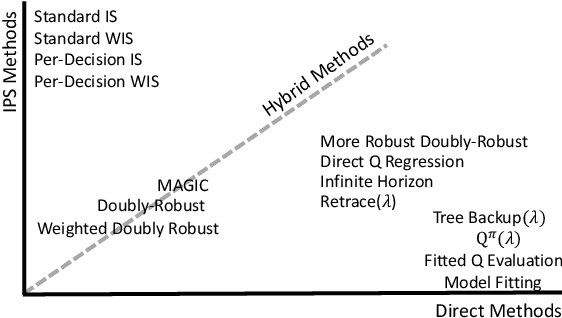


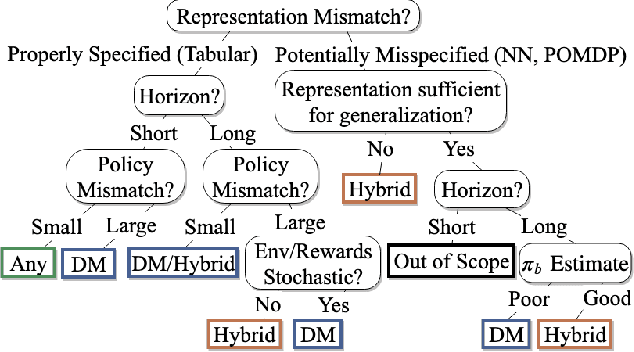
Off-policy policy evaluation (OPE) is the problem of estimating the online performance of a policy using only pre-collected historical data generated by another policy. Given the increasing interest in deploying learning-based methods for safety-critical applications, many recent OPE methods have recently been proposed. Due to disparate experimental conditions from recent literature, the relative performance of current OPE methods is not well understood. In this work, we present the first comprehensive empirical analysis of a broad suite of OPE methods. Based on thousands of experiments and detailed empirical analyses, we offer a summarized set of guidelines for effectively using OPE in practice, and suggest directions for future research.
* Main paper is 8 pages. The appendix contains many pages of tables
View paper on
 OpenReview
OpenReview