Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmphatic Temporal-Difference Learning
Paper and Code
Jul 06, 2015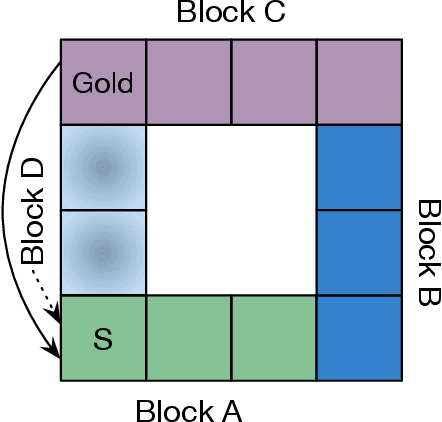
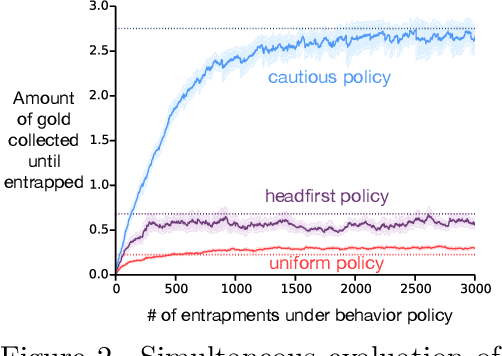
Emphatic algorithms are temporal-difference learning algorithms that change their effective state distribution by selectively emphasizing and de-emphasizing their updates on different time steps. Recent works by Sutton, Mahmood and White (2015), and Yu (2015) show that by varying the emphasis in a particular way, these algorithms become stable and convergent under off-policy training with linear function approximation. This paper serves as a unified summary of the available results from both works. In addition, we demonstrate the empirical benefits from the flexibility of emphatic algorithms, including state-dependent discounting, state-dependent bootstrapping, and the user-specified allocation of function approximation resources.
* 9 pages, accepted for presentation at European Workshop on
Reinforcement Learning
View paper on