Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEllipsis and Coreference Resolution as Question Answering
Paper and Code

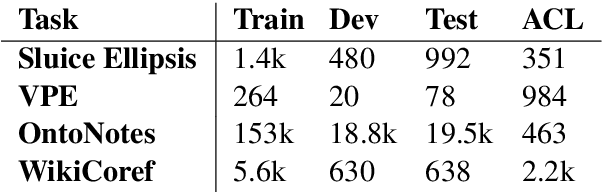

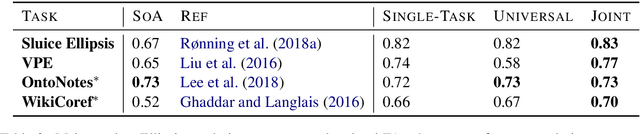
Coreference and many forms of ellipsis are similar to reading comprehension questions, in that in order to resolve these, we need to identify an appropriate text span in the previous discourse. This paper exploits this analogy and proposes to use an architecture developed for machine comprehension for ellipsis and coreference resolution. We present both single-task and joint models and evaluate them across standard benchmarks, outperforming the current state of the art for ellipsis by up to 48.5% error reduction -- and for coreference by 37.5% error reduction.
* Preprint. Work in progress
View paper on