 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELiOT : End-to-end Lidar Odometry using Transformer Framework
Paper and Code
Jul 31, 2023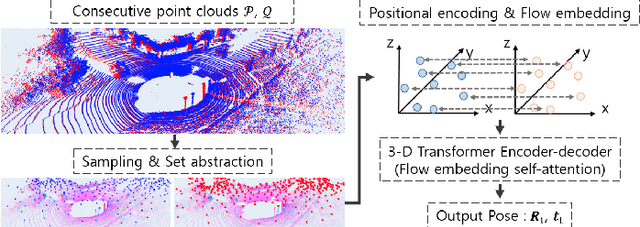
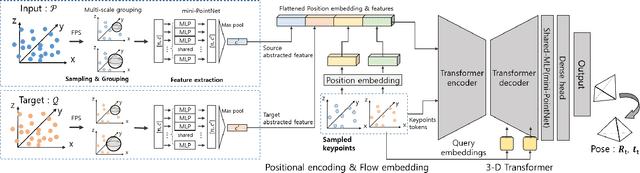
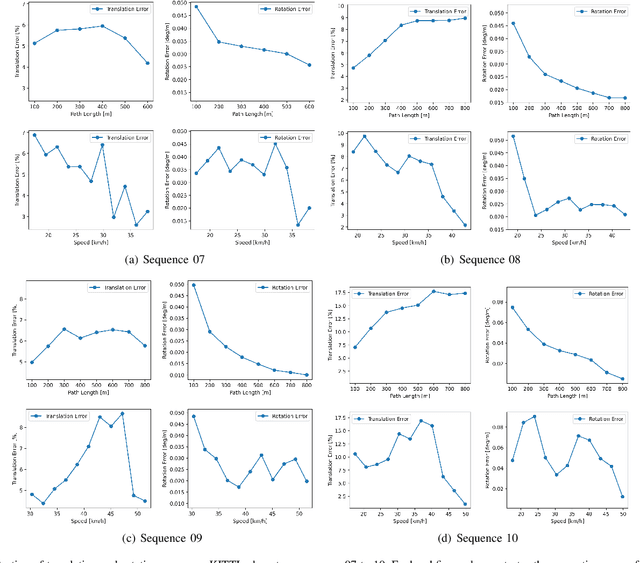
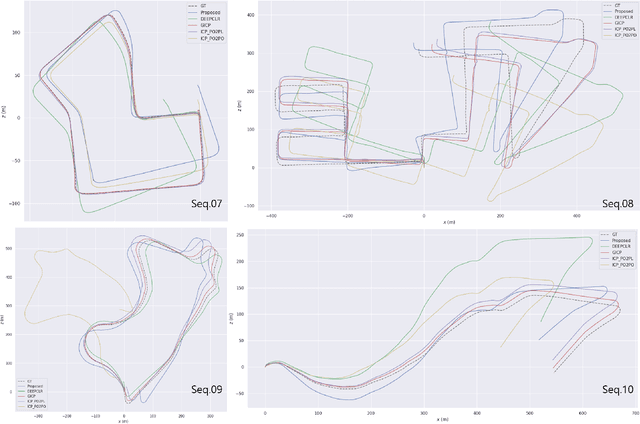
In recent years, deep-learning-based point cloud registration methods have shown significant promise. Furthermore, learning-based 3D detectors have demonstrated their effectiveness in encoding semantic information from LiDAR data. In this paper, we introduce ELiOT, an end-to-end LiDAR odometry framework built on a transformer architecture. Our proposed Self-attention flow embedding network implicitly represents the motion of sequential LiDAR scenes, bypassing the need for 3D-2D projections traditionally used in such tasks. The network pipeline, composed of a 3D transformer encoder-decoder, has shown effectiveness in predicting poses on urban datasets. In terms of translational and rotational errors, our proposed method yields encouraging results, with 7.59% and 2.67% respectively on the KITTI odometry dataset. This is achieved with an end-to-end approach that foregoes the need for conventional geometric concepts.