 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElaboration-Generating Commonsense Question Answering at Scale
Paper and Code

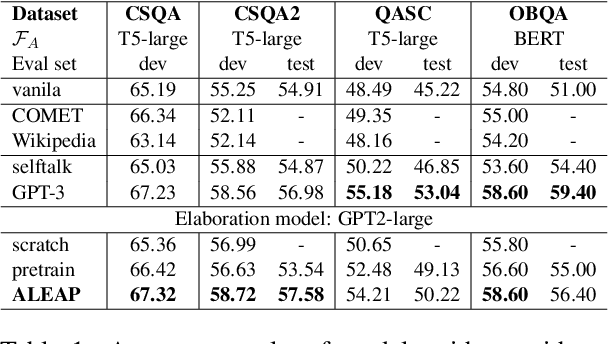
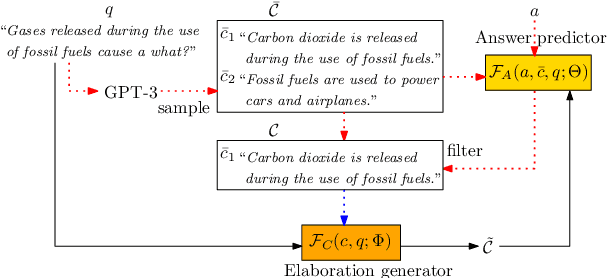

In question answering requiring common sense, language models (e.g., GPT-3) have been used to generate text expressing background knowledge that helps improve performance. Yet the cost of working with such models is very high; in this work, we finetune smaller language models to generate useful intermediate context, referred to here as elaborations. Our framework alternates between updating two language models -- an elaboration generator and an answer predictor -- allowing each to influence the other. Using less than 0.5% of the parameters of GPT-3, our model outperforms alternatives with similar sizes and closes the gap on GPT-3 on four commonsense question answering benchmarks. Human evaluations show that the quality of the generated elaborations is high.