 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Use of Limited-Memory Accelerators for Linear Learning on Heterogeneous Systems
Paper and Code
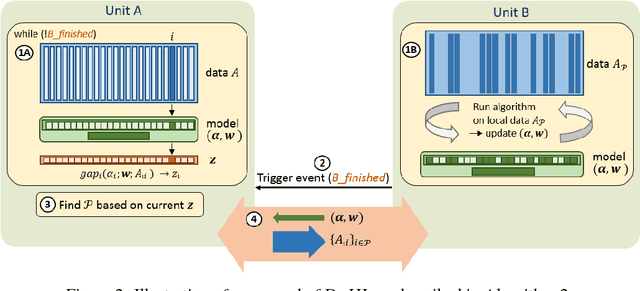
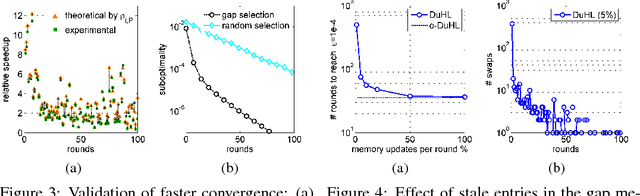
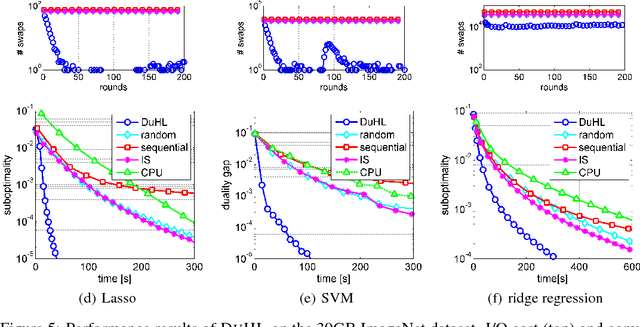
We propose a generic algorithmic building block to accelerate training of machine learning models on heterogeneous compute systems. Our scheme allows to efficiently employ compute accelerators such as GPUs and FPGAs for the training of large-scale machine learning models, when the training data exceeds their memory capacity. Also, it provides adaptivity to any system's memory hierarchy in terms of size and processing speed. Our technique is built upon novel theoretical insights regarding primal-dual coordinate methods, and uses duality gap information to dynamically decide which part of the data should be made available for fast processing. To illustrate the power of our approach we demonstrate its performance for training of generalized linear models on a large-scale dataset exceeding the memory size of a modern GPU, showing an order-of-magnitude speedup over existing approaches.