 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Reinforcement Learning for Global Decision Making in the Presence of Local Agents at Scale
Paper and Code
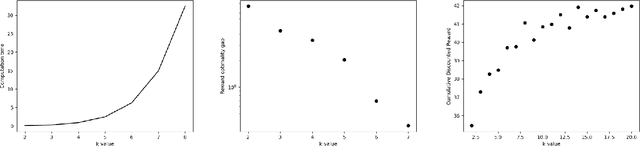
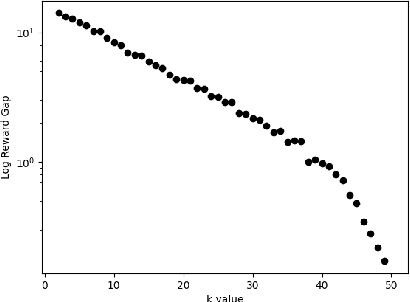
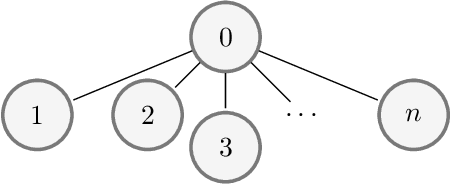
We study reinforcement learning for global decision-making in the presence of many local agents, where the global decision-maker makes decisions affecting all local agents, and the objective is to learn a policy that maximizes the rewards of both the global and the local agents. Such problems find many applications, e.g. demand response, EV charging, queueing, etc. In this setting, scalability has been a long-standing challenge due to the size of the state/action space which can be exponential in the number of agents. This work proposes the SUB-SAMPLE-Q algorithm where the global agent subsamples $k\leq n$ local agents to compute an optimal policy in time that is only exponential in $k$, providing an exponential speedup from standard methods that are exponential in $n$. We show that the learned policy converges to the optimal policy in the order of $\tilde{O}(1/\sqrt{k}+\epsilon_{k,m})$ as the number of sub-sampled agents $k$ increases, where $\epsilon_{k,m}$ is the Bellman noise. We also conduct numerical simulations in a demand-response setting and a queueing setting.