 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient nonmyopic Bayesian optimization and quadrature
Paper and Code
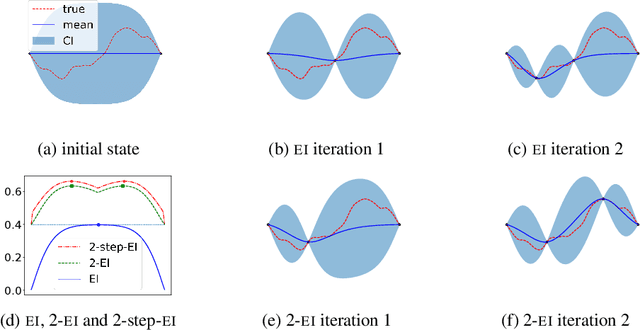

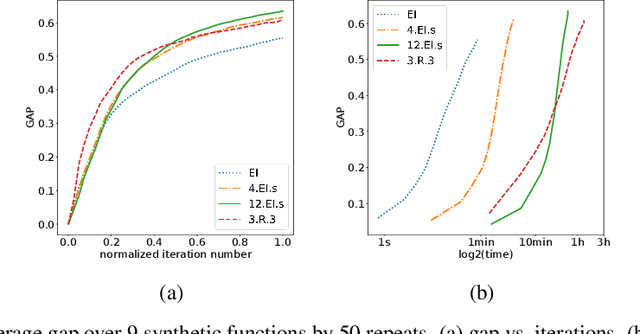
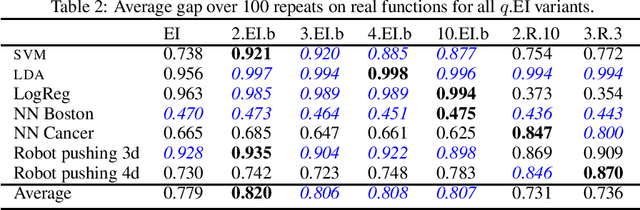
Finite-horizon sequential decision problems arise naturally in many machine learning contexts, including Bayesian optimization and Bayesian quadrature. Computing the optimal policy for such problems requires solving Bellman equations, which are generally intractable. Most existing work resorts to myopic approximations by limiting the decision horizon to only a single time-step, which can perform poorly at balancing exploration and exploitation. We propose a general framework for efficient, nonmyopic approximation of the optimal policy by drawing a connection between the optimal adaptive policy and its non-adaptive counterpart. Our proposal is to compute an optimal batch of points, then select a single point from within this batch to evaluate. We realize this idea for both Bayesian optimization and Bayesian quadrature and demonstrate that our proposed method significantly outperforms common myopic alternatives on a variety of tasks.