 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Non-Autoregressive GAN Voice Conversion using VQWav2vec Features and Dynamic Convolution
Paper and Code
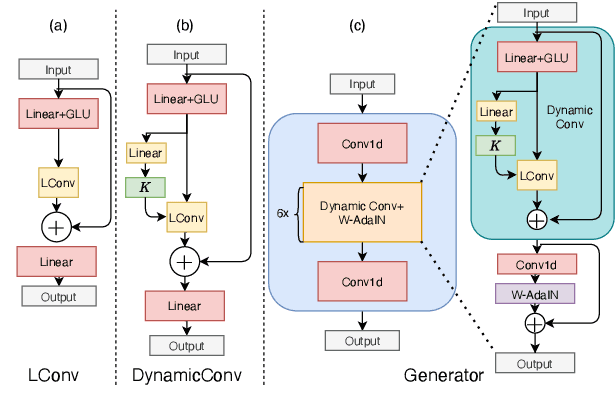
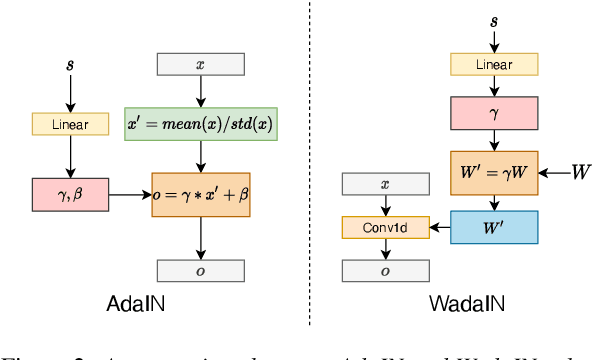
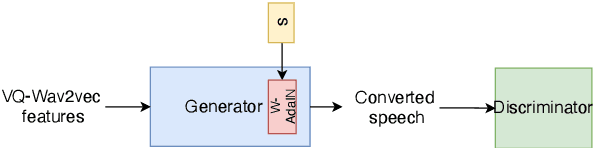

It was shown recently that a combination of ASR and TTS models yield highly competitive performance on standard voice conversion tasks such as the Voice Conversion Challenge 2020 (VCC2020). To obtain good performance both models require pretraining on large amounts of data, thereby obtaining large models that are potentially inefficient in use. In this work we present a model that is significantly smaller and thereby faster in processing while obtaining equivalent performance. To achieve this the proposed model, Dynamic-GAN-VC (DYGAN-VC), uses a non-autoregressive structure and makes use of vector quantised embeddings obtained from a VQWav2vec model. Furthermore dynamic convolution is introduced to improve speech content modeling while requiring a small number of parameters. Objective and subjective evaluation was performed using the VCC2020 task, yielding MOS scores of up to 3.86, and character error rates as low as 4.3\%. This was achieved with approximately half the number of model parameters, and up to 8 times faster decoding speed.