 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Learning of Sparse Conditional Random Fields for Supervised Sequence Labelling
Paper and Code
Jan 03, 2010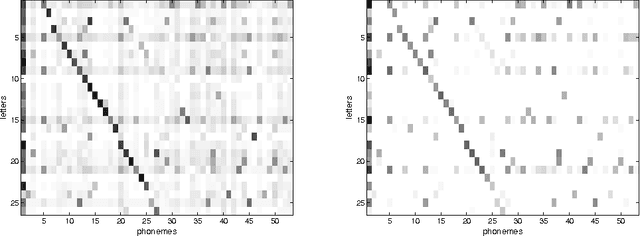

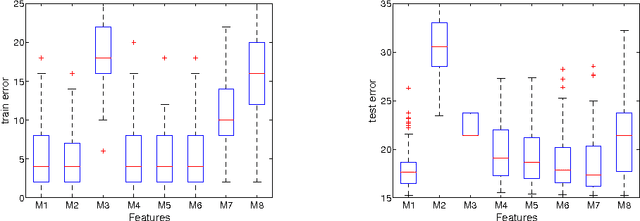
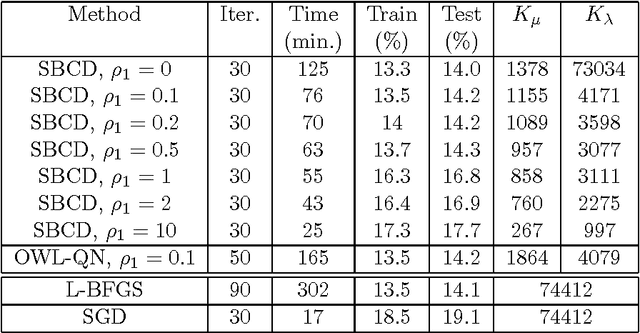
Conditional Random Fields (CRFs) constitute a popular and efficient approach for supervised sequence labelling. CRFs can cope with large description spaces and can integrate some form of structural dependency between labels. In this contribution, we address the issue of efficient feature selection for CRFs based on imposing sparsity through an L1 penalty. We first show how sparsity of the parameter set can be exploited to significantly speed up training and labelling. We then introduce coordinate descent parameter update schemes for CRFs with L1 regularization. We finally provide some empirical comparisons of the proposed approach with state-of-the-art CRF training strategies. In particular, it is shown that the proposed approach is able to take profit of the sparsity to speed up processing and hence potentially handle larger dimensional models.