 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Learning of Restricted Boltzmann Machines Using Covariance estimates
Paper and Code
Oct 25, 2018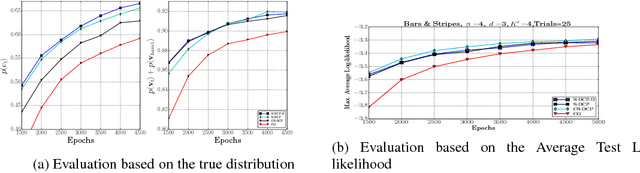
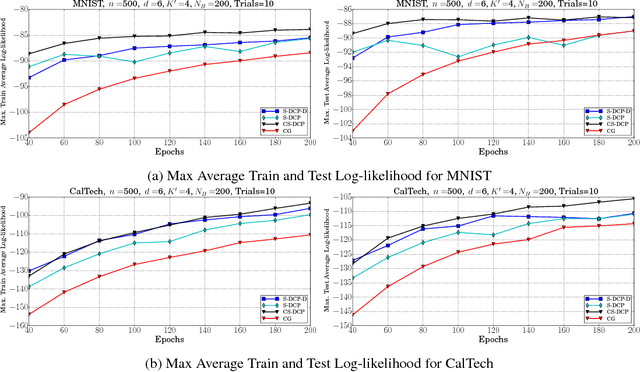

Learning of RBMs using standard algorithms such as CD(k) involves gradient descent on negative log-likelihood. One of the terms in the gradient, which is expectation of visible and hidden units is intractable and is obtained through an MCMC estimate. In this work we show that the Hessian of the log-likelihood can be written in terms of covariances of hidden and visible units and hence all elements of the Hessian can also be estimated using the same MCMC samples with minimal extra computational costs. Since inverting the Hessian may be computationally expensive, we propose an algorithm that uses inverse of the diagonal approximation of the Hessian. This essentially results in parameter-specific adaptive learning rates for the gradient descent process. We show that this algorithm improves the efficiency of learning RBMs compared to state-of-art methods. Specifically we show that using the inverse of diagonal approximation of Hessian in the stochastic DC (difference of convex functions) program approach results in very efficient learning of RBMs. We use different evaluation metrics to test the probability distribution learnt by the RBM along with the traditional criterion of average test and train log-likelihood.