 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient hyperparameter optimization by way of PAC-Bayes bound minimization
Paper and Code
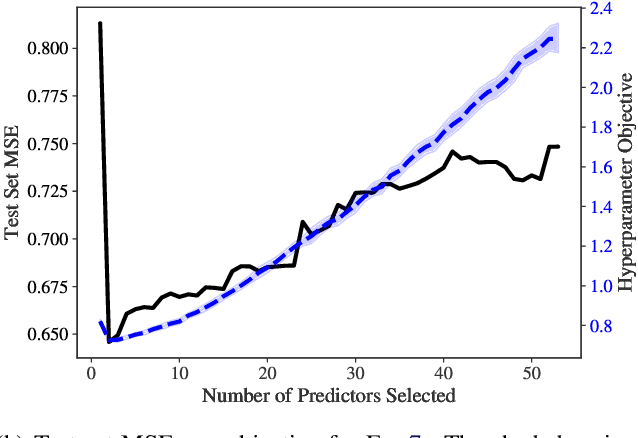
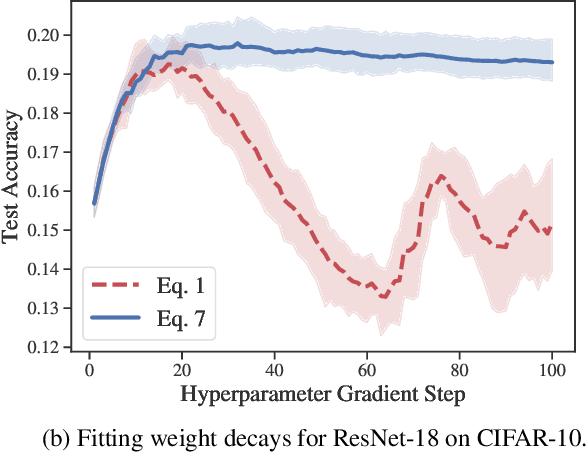
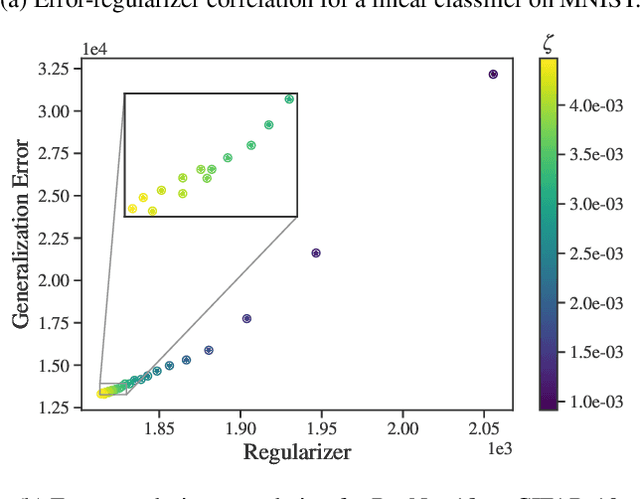
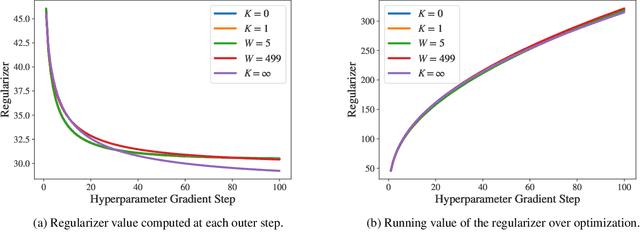
Identifying optimal values for a high-dimensional set of hyperparameters is a problem that has received growing attention given its importance to large-scale machine learning applications such as neural architecture search. Recently developed optimization methods can be used to select thousands or even millions of hyperparameters. Such methods often yield overfit models, however, leading to poor performance on unseen data. We argue that this overfitting results from using the standard hyperparameter optimization objective function. Here we present an alternative objective that is equivalent to a Probably Approximately Correct-Bayes (PAC-Bayes) bound on the expected out-of-sample error. We then devise an efficient gradient-based algorithm to minimize this objective; the proposed method has asymptotic space and time complexity equal to or better than other gradient-based hyperparameter optimization methods. We show that this new method significantly reduces out-of-sample error when applied to hyperparameter optimization problems known to be prone to overfitting.