 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Designs of SLOPE Penalty Sequences in Finite Dimension
Paper and Code
Feb 17, 2021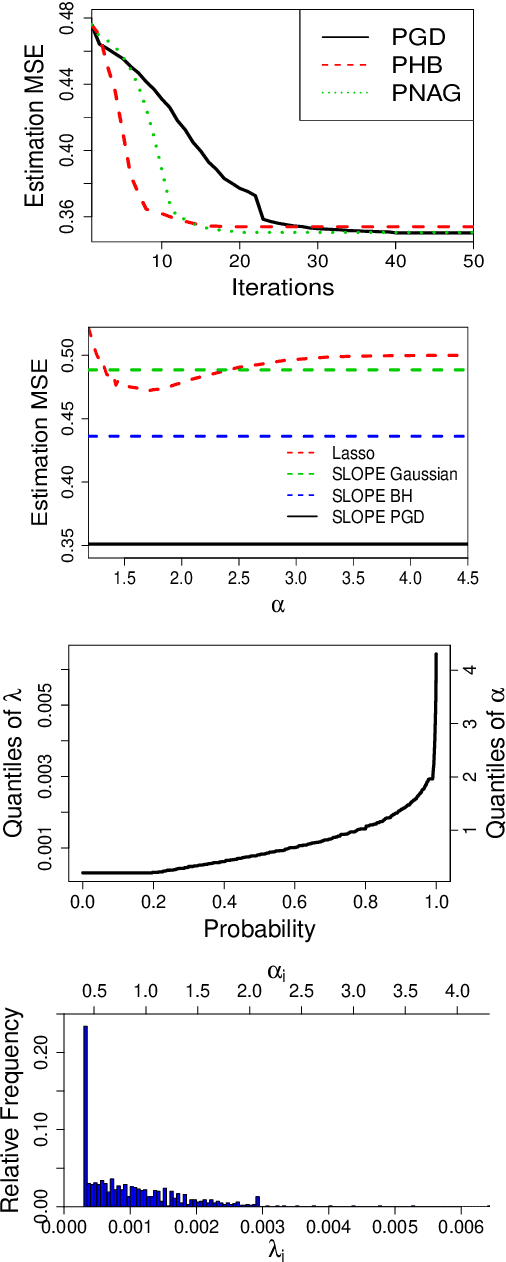
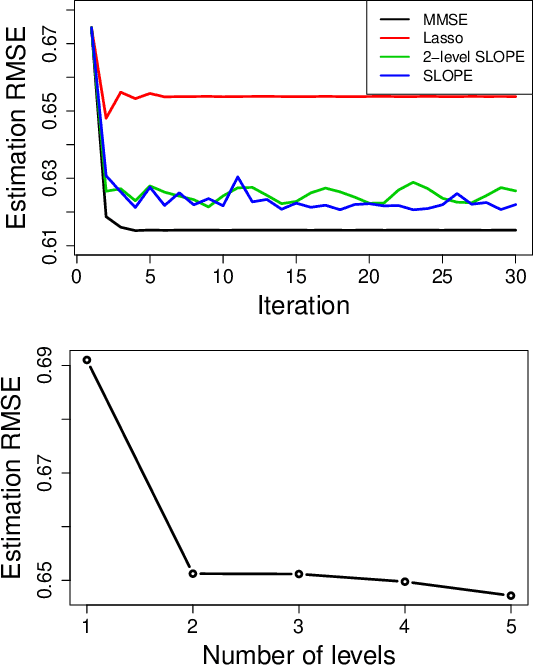
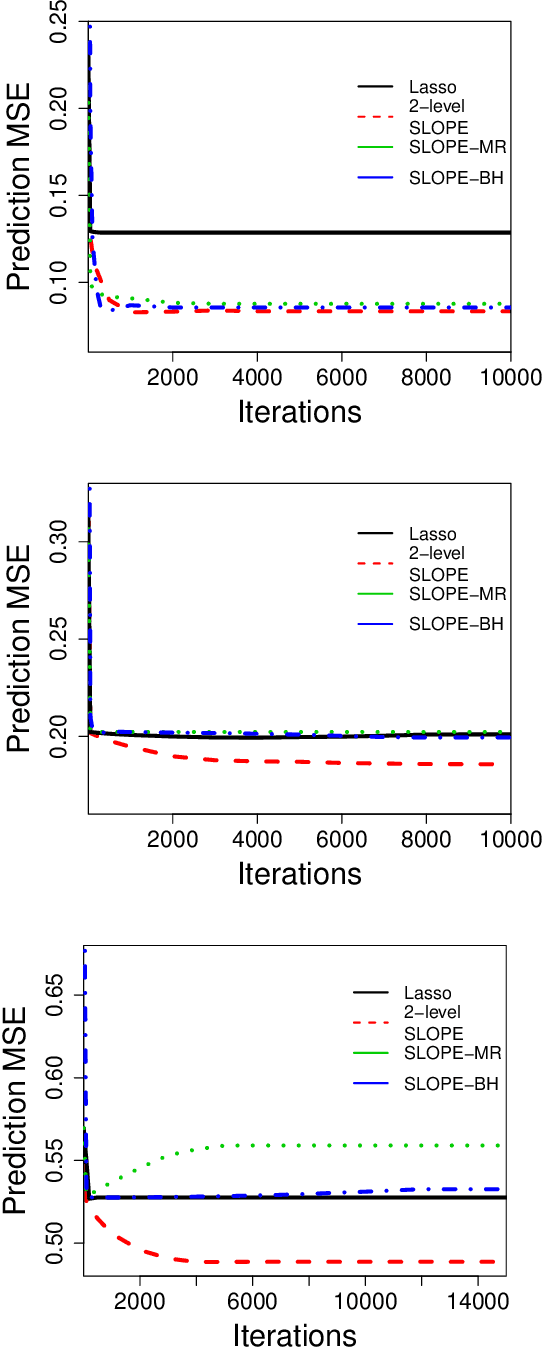
In linear regression, SLOPE is a new convex analysis method that generalizes the Lasso via the sorted L1 penalty: larger fitted coefficients are penalized more heavily. This magnitude-dependent regularization requires an input of penalty sequence $\lambda$, instead of a scalar penalty as in the Lasso case, thus making the design extremely expensive in computation. In this paper, we propose two efficient algorithms to design the possibly high-dimensional SLOPE penalty, in order to minimize the mean squared error. For Gaussian data matrices, we propose a first order Projected Gradient Descent (PGD) under the Approximate Message Passing regime. For general data matrices, we present a zero-th order Coordinate Descent (CD) to design a sub-class of SLOPE, referred to as the k-level SLOPE. Our CD allows a useful trade-off between the accuracy and the computation speed. We demonstrate the performance of SLOPE with our designs via extensive experiments on synthetic data and real-world datasets.