 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Belief Space Planning in High-Dimensional State Spaces using PIVOT: Predictive Incremental Variable Ordering Tactic
Paper and Code
Dec 29, 2021

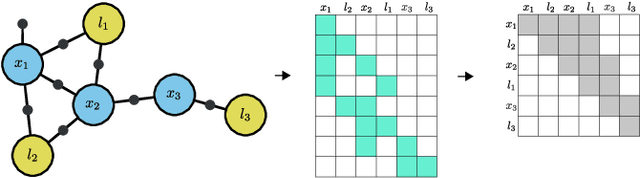
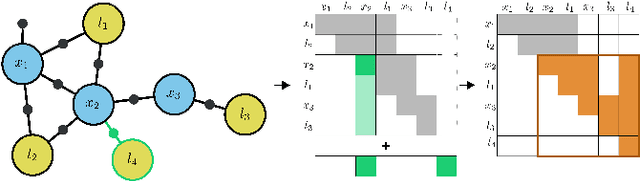
In this work, we examine the problem of online decision making under uncertainty, which we formulate as planning in the belief space. Maintaining beliefs (i.e., distributions) over high-dimensional states (e.g., entire trajectories) was not only shown to significantly improve accuracy, but also allows planning with information-theoretic objectives, as required for the tasks of active SLAM and information gathering. Nonetheless, planning under this "smoothing" paradigm holds a high computational complexity, which makes it challenging for online solution. Thus, we suggest the following idea: before planning, perform a standalone state variable reordering procedure on the initial belief, and "push forwards" all the predicted loop closing variables. Since the initial variable order determines which subset of them would be affected by incoming updates, such reordering allows us to minimize the total number of affected variables, and reduce the computational complexity of candidate evaluation during planning. We call this approach PIVOT: Predictive Incremental Variable Ordering Tactic. Applying this tactic can also improve the state inference efficiency; if we maintain the PIVOT order after the planning session, then we should similarly reduce the cost of loop closures, when they actually occur. To demonstrate its effectiveness, we applied PIVOT in a realistic active SLAM simulation, where we managed to significantly reduce the computation time of both the planning and inference sessions. The approach is applicable to general distributions, and induces no loss in accuracy.