 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Adaptive Linear Regression in Semi-Supervised Settings
Paper and Code
Aug 19, 2017


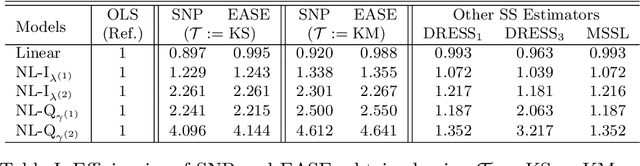
We consider the linear regression problem under semi-supervised settings wherein the available data typically consists of: (i) a small or moderate sized 'labeled' data, and (ii) a much larger sized 'unlabeled' data. Such data arises naturally from settings where the outcome, unlike the covariates, is expensive to obtain, a frequent scenario in modern studies involving large databases like electronic medical records (EMR). Supervised estimators like the ordinary least squares (OLS) estimator utilize only the labeled data. It is often of interest to investigate if and when the unlabeled data can be exploited to improve estimation of the regression parameter in the adopted linear model. In this paper, we propose a class of 'Efficient and Adaptive Semi-Supervised Estimators' (EASE) to improve estimation efficiency. The EASE are two-step estimators adaptive to model mis-specification, leading to improved (optimal in some cases) efficiency under model mis-specification, and equal (optimal) efficiency under a linear model. This adaptive property, often unaddressed in the existing literature, is crucial for advocating 'safe' use of the unlabeled data. The construction of EASE primarily involves a flexible 'semi-non-parametric' imputation, including a smoothing step that works well even when the number of covariates is not small; and a follow up 'refitting' step along with a cross-validation (CV) strategy both of which have useful practical as well as theoretical implications towards addressing two important issues: under-smoothing and over-fitting. We establish asymptotic results including consistency, asymptotic normality and the adaptive properties of EASE. We also provide influence function expansions and a 'double' CV strategy for inference. The results are further validated through extensive simulations, followed by application to an EMR study on auto-immunity.