 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Algorithms for Learning to Control Bandits with Unobserved Contexts
Paper and Code
Feb 02, 2022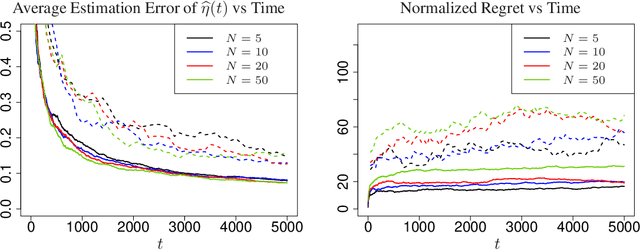
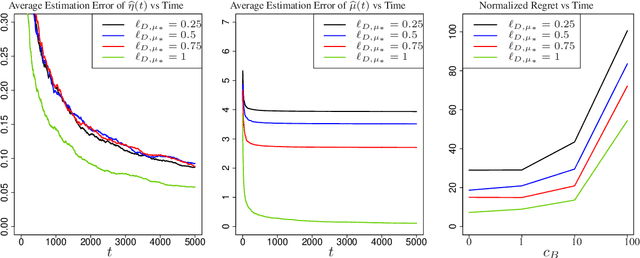
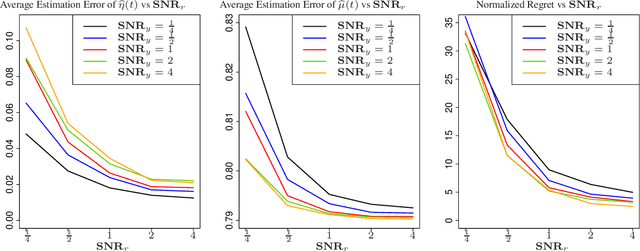
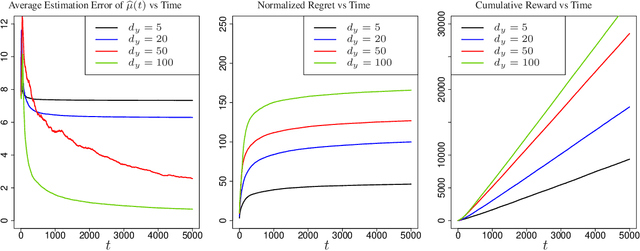
Contextual bandits are widely-used in the study of learning-based control policies for finite action spaces. While the problem is well-studied for bandits with perfectly observed context vectors, little is known about the case of imperfectly observed contexts. For this setting, existing approaches are inapplicable and new conceptual and technical frameworks are required. We present an implementable posterior sampling algorithm for bandits with imperfect context observations and study its performance for learning optimal decisions. The provided numerical results relate the performance of the algorithm to different quantities of interest including the number of arms, dimensions, observation matrices, posterior rescaling factors, and signal-to-noise ratios. In general, the proposed algorithm exposes efficiency in learning from the noisy imperfect observations and taking actions accordingly. Enlightening understandings the analyses provide as well as interesting future directions it points to, are discussed as well.