 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Demonstration Annotation for In-Context Learning via Language Model-Based Determinantal Point Process
Paper and Code
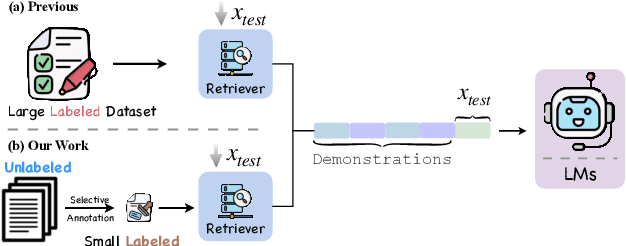
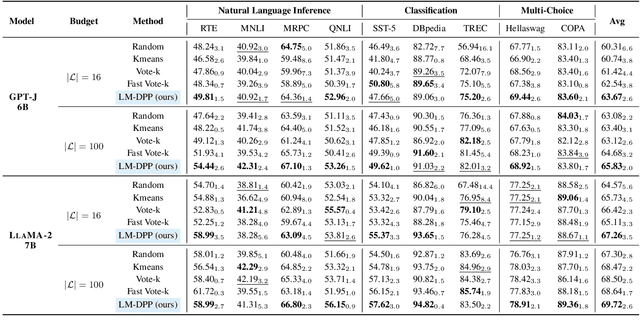
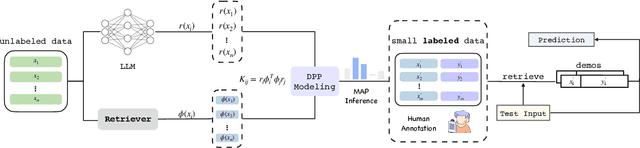
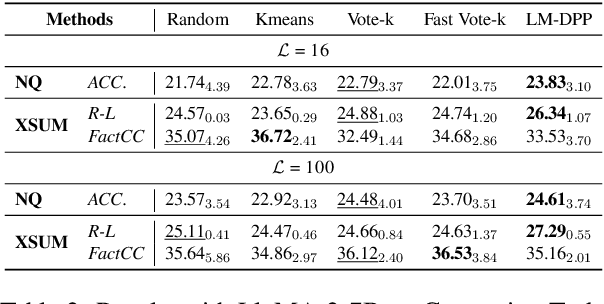
In-context learning (ICL) is a few-shot learning paradigm that involves learning mappings through input-output pairs and appropriately applying them to new instances. Despite the remarkable ICL capabilities demonstrated by Large Language Models (LLMs), existing works are highly dependent on large-scale labeled support sets, not always feasible in practical scenarios. To refine this approach, we focus primarily on an innovative selective annotation mechanism, which precedes the standard demonstration retrieval. We introduce the Language Model-based Determinant Point Process (LM-DPP) that simultaneously considers the uncertainty and diversity of unlabeled instances for optimal selection. Consequently, this yields a subset for annotation that strikes a trade-off between the two factors. We apply LM-DPP to various language models, including GPT-J, LlaMA, and GPT-3. Experimental results on 9 NLU and 2 Generation datasets demonstrate that LM-DPP can effectively select canonical examples. Further analysis reveals that LLMs benefit most significantly from subsets that are both low uncertainty and high diversity.