 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeED2: Two-stage Active Learning for Error Detection -- Technical Report
Paper and Code
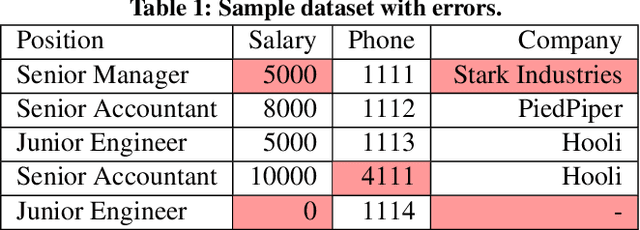
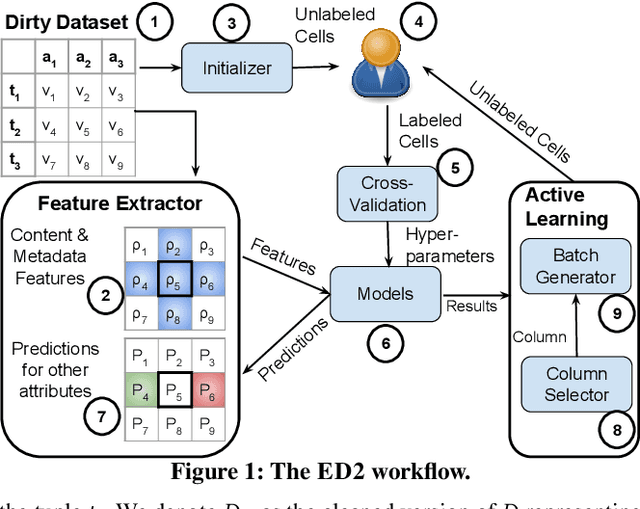
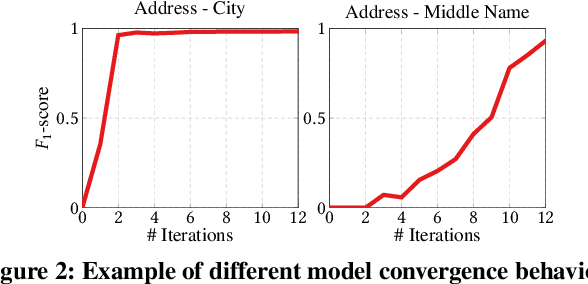
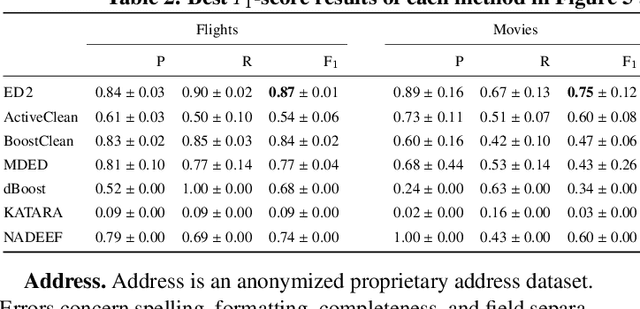
Traditional error detection approaches require user-defined parameters and rules. Thus, the user has to know both the error detection system and the data. However, we can also formulate error detection as a semi-supervised classification problem that only requires domain expertise. The challenges for such an approach are twofold: (1) to represent the data in a way that enables a classification model to identify various kinds of data errors, and (2) to pick the most promising data values for learning. In this paper, we address these challenges with ED2, our new example-driven error detection method. First, we present a new two-dimensional multi-classifier sampling strategy for active learning. Second, we propose novel multi-column features. The combined application of these techniques provides fast convergence of the classification task with high detection accuracy. On several real-world datasets, ED2 requires, on average, less than 1% labels to outperform existing error detection approaches. This report extends the peer-reviewed paper "ED2: A Case for Active Learning in Error Detection". All source code related to this project is available on GitHub.