 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-LANG: Energy-Based Joint Inferencing of Super and Swift Language Models
Paper and Code
Mar 01, 2022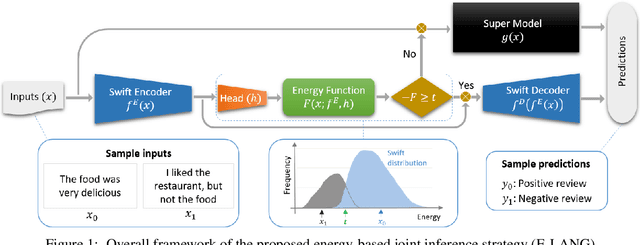


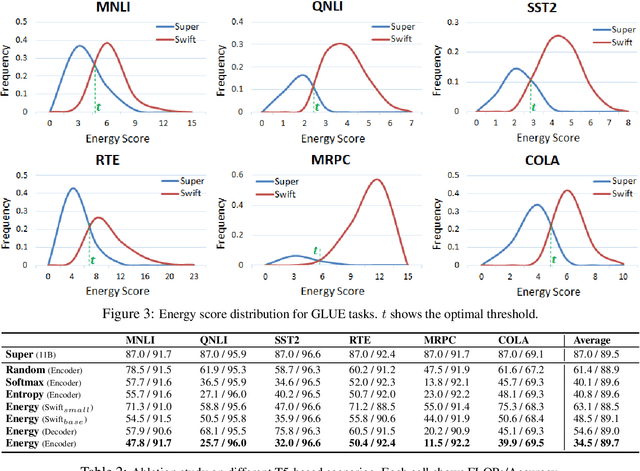
Building huge and highly capable language models has been a trend in the past years. Despite their great performance, they incur high computational cost. A common solution is to apply model compression or choose light-weight architectures, which often need a separate fixed-size model for each desirable computational budget, and may lose performance in case of heavy compression. This paper proposes an effective dynamic inference approach, called E-LANG, which distributes the inference between large accurate Super-models and light-weight Swift models. To this end, a decision making module routes the inputs to Super or Swift models based on the energy characteristics of the representations in the latent space. This method is easily adoptable and architecture agnostic. As such, it can be applied to black-box pre-trained models without a need for architectural manipulations, reassembling of modules, or re-training. Unlike existing methods that are only applicable to encoder-only backbones and classification tasks, our method also works for encoder-decoder structures and sequence-to-sequence tasks such as translation. The E-LANG performance is verified through a set of experiments with T5 and BERT backbones on GLUE, SuperGLUE, and WMT. In particular, we outperform T5-11B with an average computations speed-up of 3.3$\times$ on GLUE and 2.9$\times$ on SuperGLUE. We also achieve BERT-based SOTA on GLUE with 3.2$\times$ less computations. Code and demo are available in the supplementary materials.