 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamics of Meta-learning Representation in the Teacher-student Scenario
Paper and Code
Aug 22, 2024
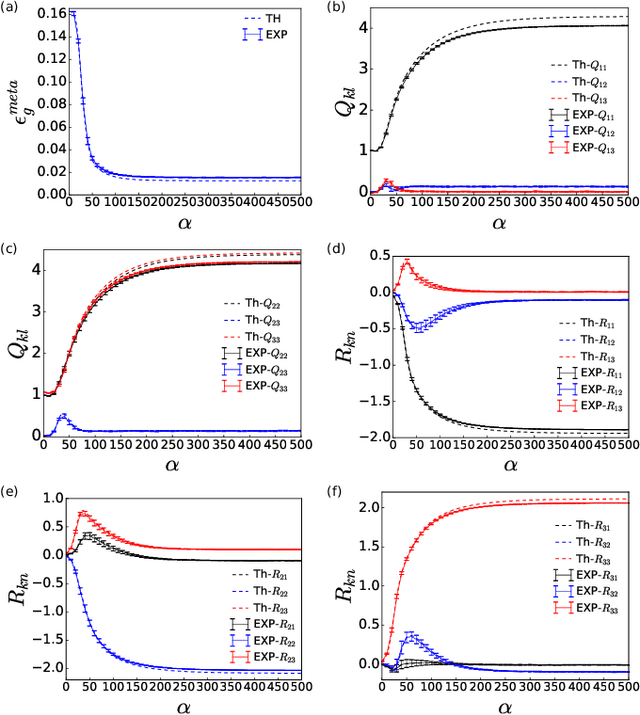
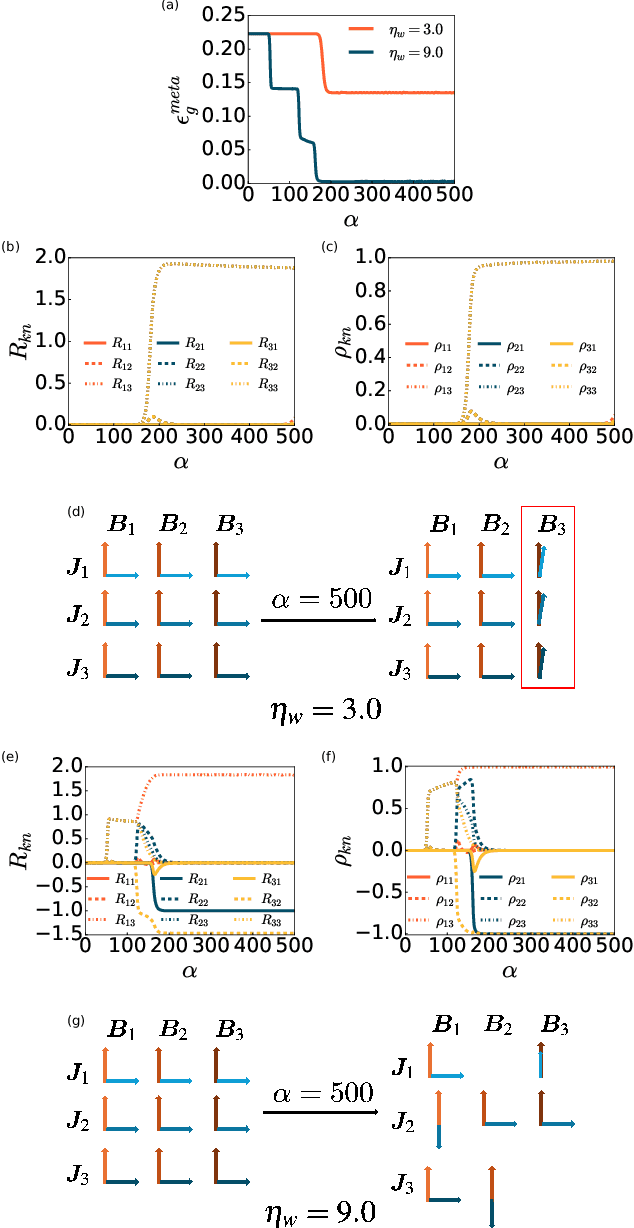

Gradient-based meta-learning algorithms have gained popularity for their ability to train models on new tasks using limited data. Empirical observations indicate that such algorithms are able to learn a shared representation across tasks, which is regarded as a key factor in their success. However, the in-depth theoretical understanding of the learning dynamics and the origin of the shared representation remains underdeveloped. In this work, we investigate the meta-learning dynamics of the non-linear two-layer neural networks trained on streaming tasks in the teach-student scenario. Through the lens of statistical physics analysis, we characterize the macroscopic behavior of the meta-training processes, the formation of the shared representation, and the generalization ability of the model on new tasks. The analysis also points to the importance of the choice of certain hyper-parameters of the learning algorithms.