 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Regret of Adaptive Gradient Methods for Strongly Convex Problems
Paper and Code
Sep 04, 2022
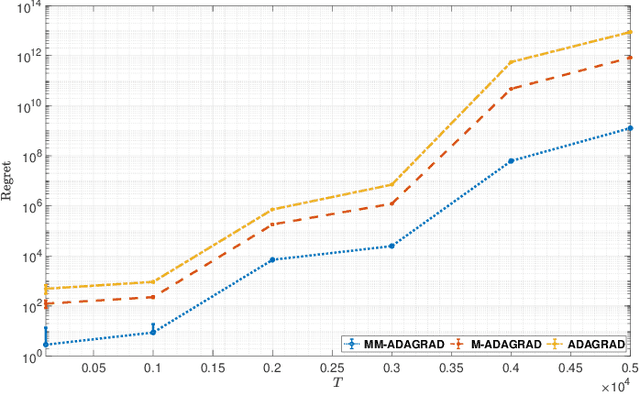
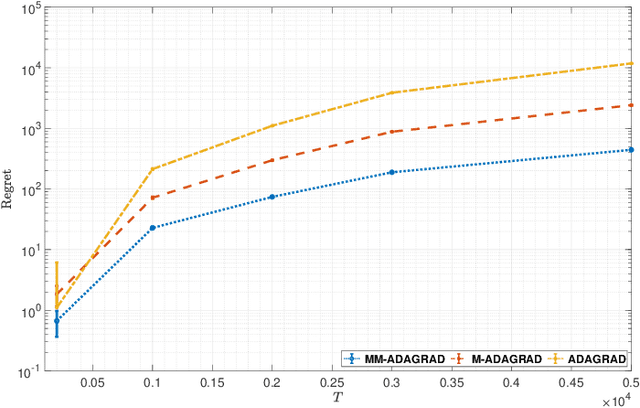
Adaptive gradient algorithms such as ADAGRAD and its variants have gained popularity in the training of deep neural networks. While many works as for adaptive methods have focused on the static regret as a performance metric to achieve a good regret guarantee, the dynamic regret analyses of these methods remain unclear. As opposed to the static regret, dynamic regret is considered to be a stronger concept of performance measurement in the sense that it explicitly elucidates the non-stationarity of the environment. In this paper, we go through a variant of ADAGRAD (referred to as M-ADAGRAD ) in a strong convex setting via the notion of dynamic regret, which measures the performance of an online learner against a reference (optimal) solution that may change over time. We demonstrate a regret bound in terms of the path-length of the minimizer sequence that essentially reflects the non-stationarity of environments. In addition, we enhance the dynamic regret bound by exploiting the multiple accesses of the gradient to the learner in each round. Empirical results indicate that M-ADAGRAD works also well in practice.