 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Action Recognition: A convolutional neural network model for temporally organized joint location data
Paper and Code
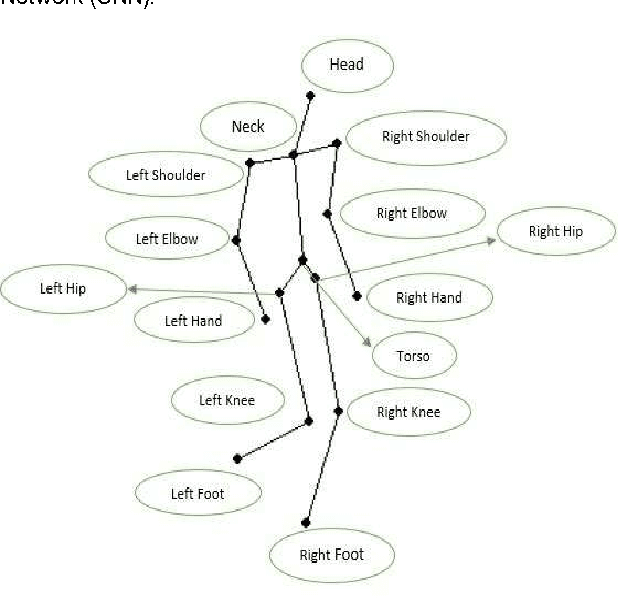
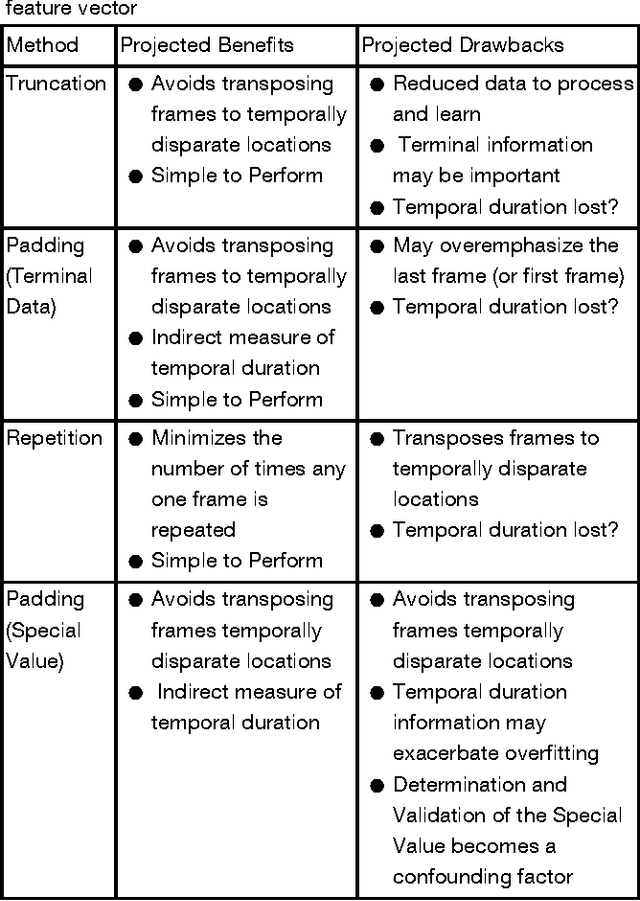

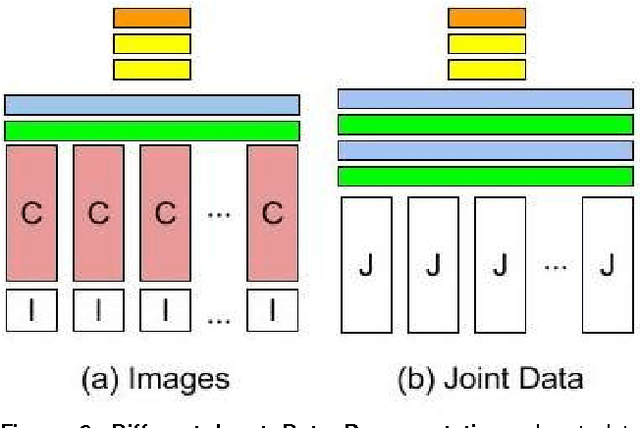
Motivation: Recognizing human actions in a video is a challenging task which has applications in various fields. Previous works in this area have either used images from a 2D or 3D camera. Few have used the idea that human actions can be easily identified by the movement of the joints in the 3D space and instead used a Recurrent Neural Network (RNN) for modeling. Convolutional neural networks (CNN) have the ability to recognise even the complex patterns in data which makes it suitable for detecting human actions. Thus, we modeled a CNN which can predict the human activity using the joint data. Furthermore, using the joint data representation has the benefit of lower dimensionality than image or video representations. This makes our model simpler and faster than the RNN models. In this study, we have developed a six layer convolutional network, which reduces each input feature vector of the form 15x1961x4 to an one dimensional binary vector which gives us the predicted activity. Results: Our model is able to recognise an activity correctly upto 87% accuracy. Joint data is taken from the Cornell Activity Datasets which have day to day activities like talking, relaxing, eating, cooking etc.