 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Path Style Learning for End-to-End Noise-Robust Speech Recognition
Paper and Code
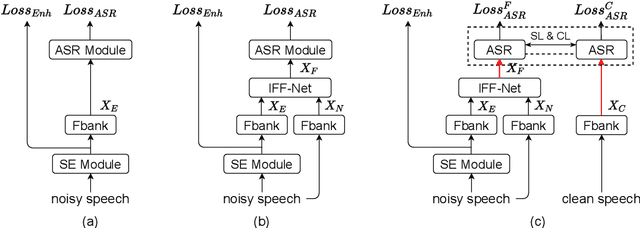



Noise-robust automatic speech recognition degrades significantly in face of over-suppression problem, which usually exists in the front-end speech enhancement module. To alleviate such issue, we propose novel dual-path style learning for end-to-end noise-robust automatic speech recognition (DPSL-ASR). Specifically, the proposed DPSL-ASR approach introduces clean feature along with fused feature by the IFF-Net as dual-path inputs to recover the over-suppressed information. Furthermore, we propose style learning to learn abundant details and latent information by mapping fused feature to clean feature. Besides, we also utilize the consistency loss to minimize the distance of decoded embeddings between two paths. Experimental results show that the proposed DPSL-ASR approach achieves relative word error rate (WER) reductions of 10.6% and 8.6%, on RATS Channel-A dataset and CHiME-4 1-Channel Track dataset, respectively. The visualizations of intermediate embeddings also indicate that the proposed DPSL-ASR can learn more details than the best baseline. Our code implementation is available at Github: https://github.com/YUCHEN005/DPSL-ASR.