 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRIVE: Machine Learning to Identify Drivers of Cancer with High-Dimensional Genomic Data & Imputed Labels
Paper and Code
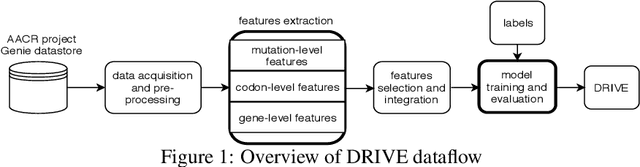
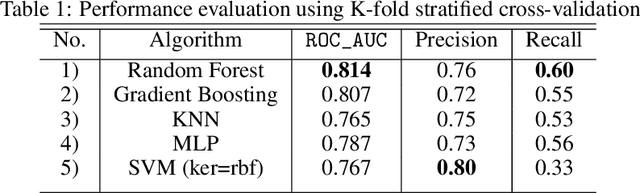
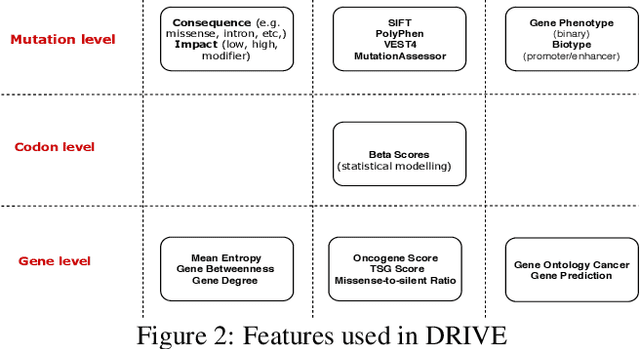

Identifying the mutations that drive cancer growth is key in clinical decision making and precision oncology. As driver mutations confer selective advantage and thus have an increased likelihood of occurrence, frequency-based statistical models are currently favoured. These methods are not suited to rare, low frequency, driver mutations. The alternative approach to address this is through functional-impact scores, however methods using this approach are highly prone to false positives. In this paper, we propose a novel combination method for driver mutation identification, which uses the power of both statistical modelling and functional-impact based methods. Initial results show this approach outperforms the state-of-the-art methods in terms of precision, and provides comparable performance in terms of area under receiver operating characteristic curves (AU-ROC). We believe that data-driven systems based on machine learning, such as these, will become an integral part of precision oncology in the near future.