 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRACO: Decentralized Asynchronous Federated Learning over Continuous Row-Stochastic Network Matrices
Paper and Code
Jun 19, 2024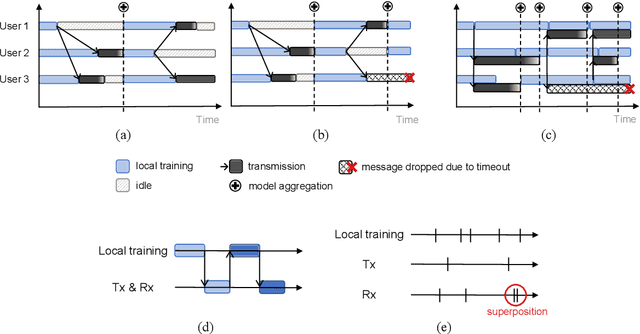
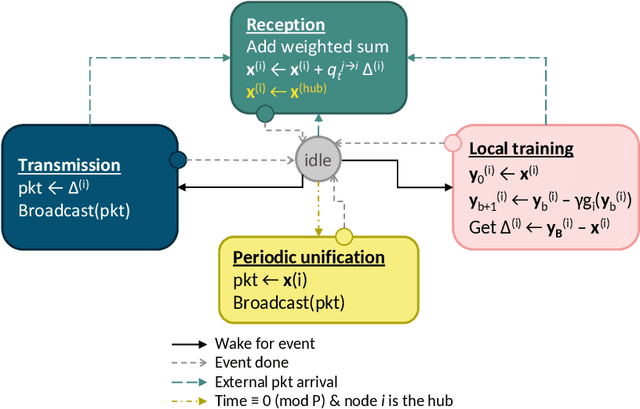
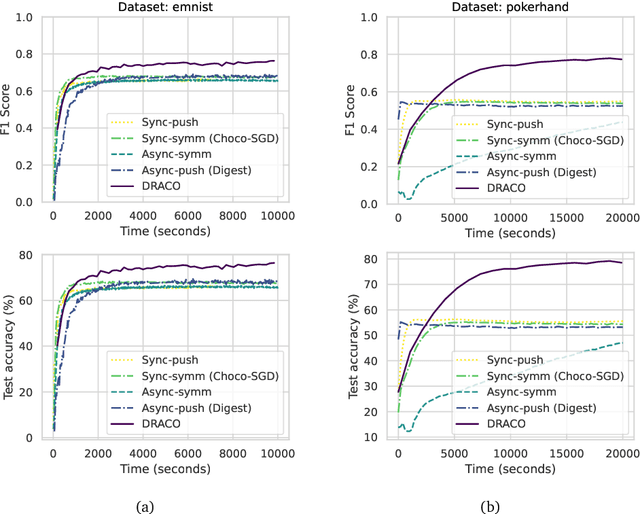
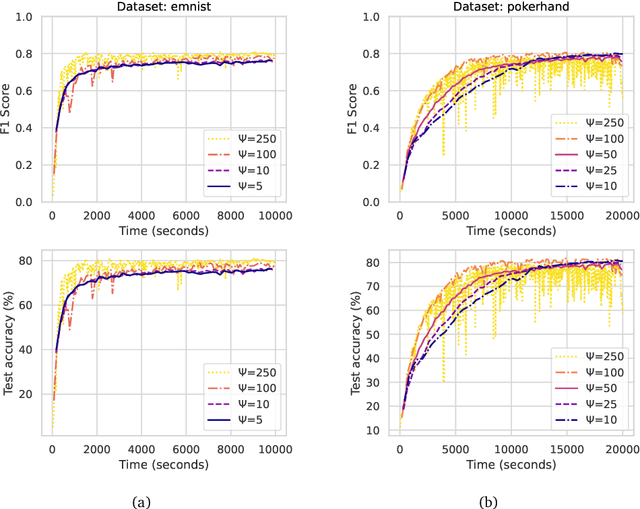
Recent developments and emerging use cases, such as smart Internet of Things (IoT) and Edge AI, have sparked considerable interest in the training of neural networks over fully decentralized (serverless) networks. One of the major challenges of decentralized learning is to ensure stable convergence without resorting to strong assumptions applied for each agent regarding data distributions or updating policies. To address these issues, we propose DRACO, a novel method for decentralized asynchronous Stochastic Gradient Descent (SGD) over row-stochastic gossip wireless networks by leveraging continuous communication. Our approach enables edge devices within decentralized networks to perform local training and model exchanging along a continuous timeline, thereby eliminating the necessity for synchronized timing. The algorithm also features a specific technique of decoupling communication and computation schedules, which empowers complete autonomy for all users and manageable instructions for stragglers. Through a comprehensive convergence analysis, we highlight the advantages of asynchronous and autonomous participation in decentralized optimization. Our numerical experiments corroborate the efficacy of the proposed technique.