 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgedpVAEs: Fixing Sample Generation for Regularized VAEs
Paper and Code
Nov 24, 2019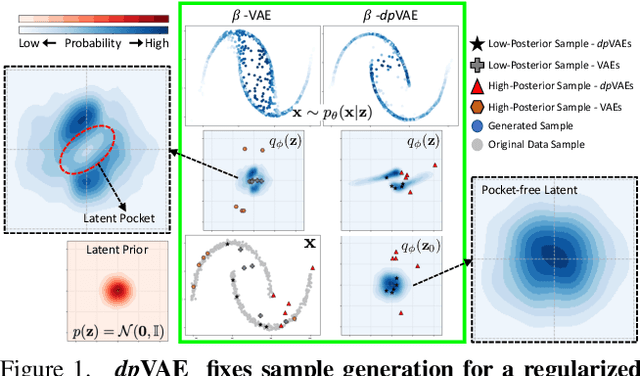
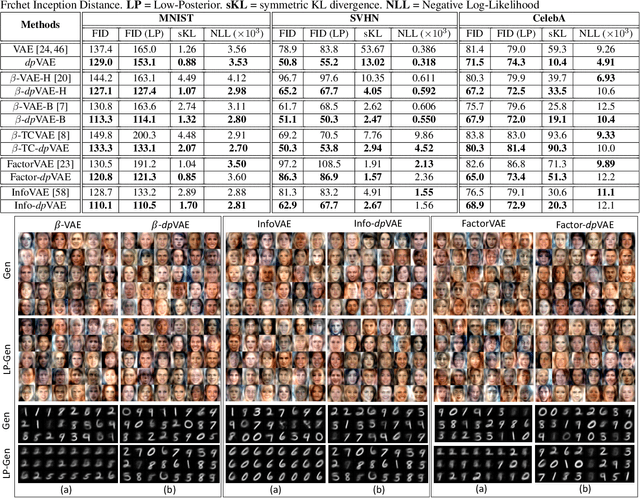
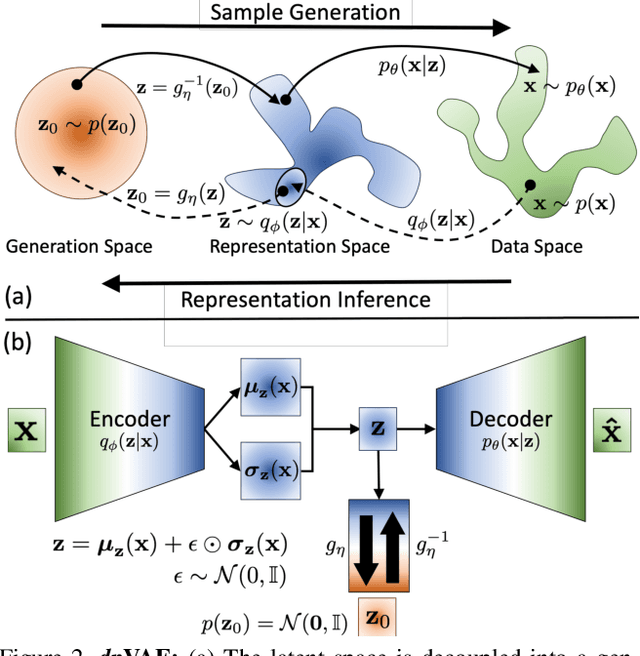
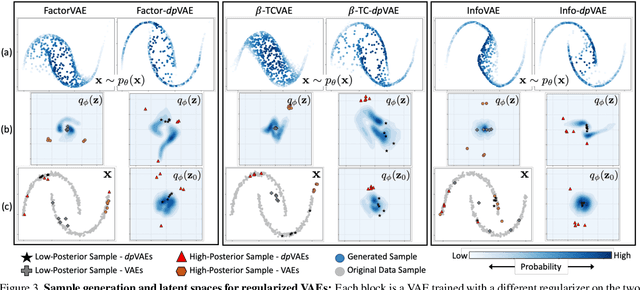
Unsupervised representation learning via generative modeling is a staple to many computer vision applications in the absence of labeled data. Variational Autoencoders (VAEs) are powerful generative models that learn representations useful for data generation. However, due to inherent challenges in the training objective, VAEs fail to learn useful representations amenable for downstream tasks. Regularization-based methods that attempt to improve the representation learning aspect of VAEs come at a price: poor sample generation. In this paper, we explore this representation-generation trade-off for regularized VAEs and introduce a new family of priors, namely decoupled priors, or dpVAEs, that decouple the representation space from the generation space. This decoupling enables the use of VAE regularizers on the representation space without impacting the distribution used for sample generation, and thereby reaping the representation learning benefits of the regularizations without sacrificing the sample generation. dpVAE leverages invertible networks to learn a bijective mapping from an arbitrarily complex representation distribution to a simple, tractable, generative distribution. Decoupled priors can be adapted to the state-of-the-art VAE regularizers without additional hyperparameter tuning. We showcase the use of dpVAEs with different regularizers. Experiments on MNIST, SVHN, and CelebA demonstrate, quantitatively and qualitatively, that dpVAE fixes sample generation for regularized VAEs.