 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoubly Robust Thompson Sampling for linear payoffs
Paper and Code
Feb 01, 2021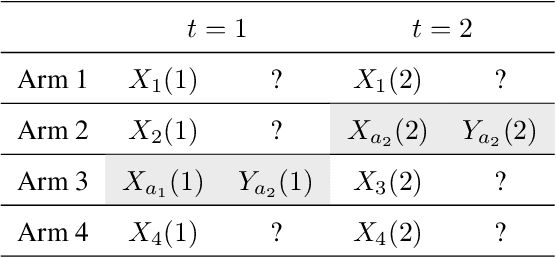
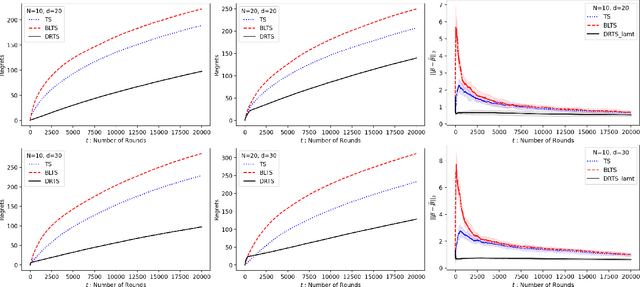
A challenging aspect of the bandit problem is that a stochastic reward is observed only for the chosen arm and the rewards of other arms remain missing. Since the arm choice depends on the past context and reward pairs, the contexts of chosen arms suffer from correlation and render the analysis difficult. We propose a novel multi-armed contextual bandit algorithm called Doubly Robust (DR) Thompson Sampling (TS) that applies the DR technique used in missing data literature to TS. The proposed algorithm improves the bound of TS by a factor of $\sqrt{d}$, where $d$ is the dimension of the context. A benefit of the proposed method is that it uses all the context data, chosen or not chosen, thus allowing to circumvent the technical definition of unsaturated arms used in theoretical analysis of TS. Empirical studies show the advantage of the proposed algorithm over TS.