 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Doubly Robust Thompson Sampling for Generalized Linear Contextual Bandits
Paper and Code
Sep 15, 2022


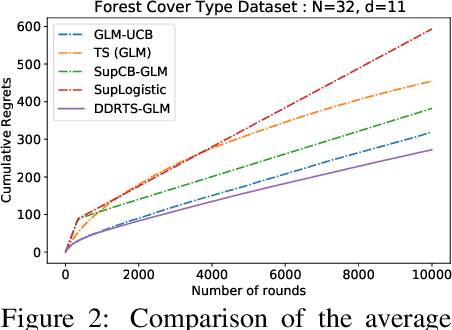
We propose a novel contextual bandit algorithm for generalized linear rewards with an $\tilde{O}(\sqrt{\kappa^{-1} \phi T})$ regret over $T$ rounds where $\phi$ is the minimum eigenvalue of the covariance of contexts and $\kappa$ is a lower bound of the variance of rewards. In several practical cases where $\phi=O(d)$, our result is the first regret bound for generalized linear model (GLM) bandits with the order $\sqrt{d}$ without relying on the approach of Auer [2002]. We achieve this bound using a novel estimator called double doubly-robust (DDR) estimator, a subclass of doubly-robust (DR) estimator but with a tighter error bound. The approach of Auer [2002] achieves independence by discarding the observed rewards, whereas our algorithm achieves independence considering all contexts using our DDR estimator. We also provide an $O(\kappa^{-1} \phi \log (NT) \log T)$ regret bound for $N$ arms under a probabilistic margin condition. Regret bounds under the margin condition are given by Bastani and Bayati [2020] and Bastani et al. [2021] under the setting that contexts are common to all arms but coefficients are arm-specific. When contexts are different for all arms but coefficients are common, ours is the first regret bound under the margin condition for linear models or GLMs. We conduct empirical studies using synthetic data and real examples, demonstrating the effectiveness of our algorithm.