 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Discard All the Biased Instances: Investigating a Core Assumption in Dataset Bias Mitigation Techniques
Paper and Code
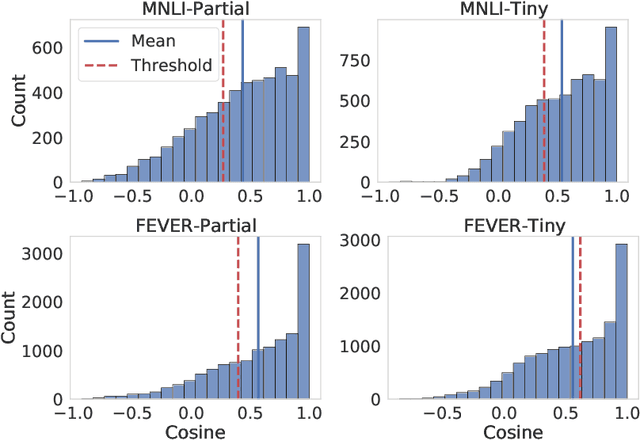
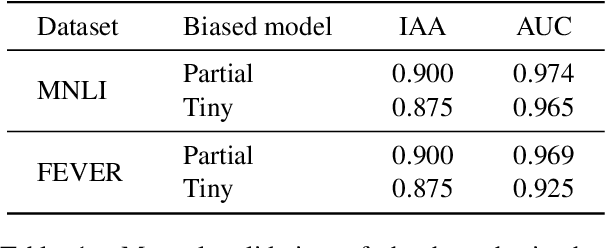
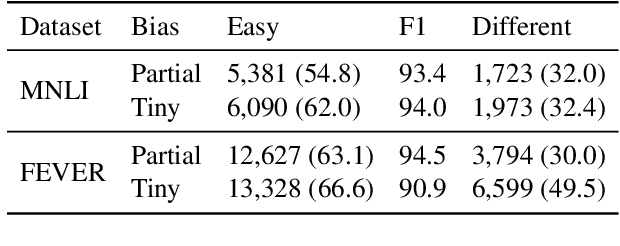
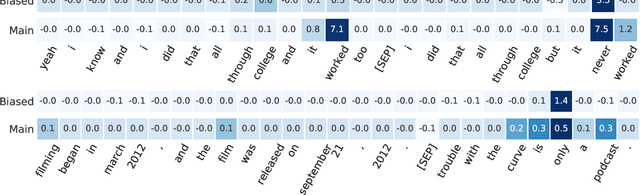
Existing techniques for mitigating dataset bias often leverage a biased model to identify biased instances. The role of these biased instances is then reduced during the training of the main model to enhance its robustness to out-of-distribution data. A common core assumption of these techniques is that the main model handles biased instances similarly to the biased model, in that it will resort to biases whenever available. In this paper, we show that this assumption does not hold in general. We carry out a critical investigation on two well-known datasets in the domain, MNLI and FEVER, along with two biased instance detection methods, partial-input and limited-capacity models. Our experiments show that in around a third to a half of instances, the biased model is unable to predict the main model's behavior, highlighted by the significantly different parts of the input on which they base their decisions. Based on a manual validation, we also show that this estimate is highly in line with human interpretation. Our findings suggest that down-weighting of instances detected by bias detection methods, which is a widely-practiced procedure, is an unnecessary waste of training data. We release our code to facilitate reproducibility and future research.