 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Adjusted Regression or: ERM May Already Learn Features Sufficient for Out-of-Distribution Generalization
Paper and Code
Feb 14, 2022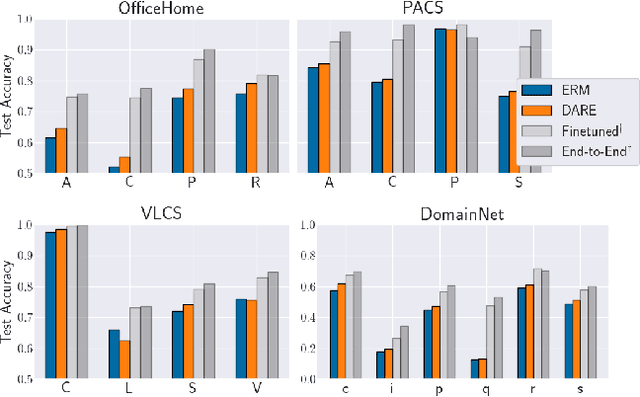



A common explanation for the failure of deep networks to generalize out-of-distribution is that they fail to recover the "correct" features. Focusing on the domain generalization setting, we challenge this notion with a simple experiment which suggests that ERM already learns sufficient features and that the current bottleneck is not feature learning, but robust regression. We therefore argue that devising simpler methods for learning predictors on existing features is a promising direction for future research. Towards this end, we introduce Domain-Adjusted Regression (DARE), a convex objective for learning a linear predictor that is provably robust under a new model of distribution shift. Rather than learning one function, DARE performs a domain-specific adjustment to unify the domains in a canonical latent space and learns to predict in this space. Under a natural model, we prove that the DARE solution is the minimax-optimal predictor for a constrained set of test distributions. Further, we provide the first finite-environment convergence guarantee to the minimax risk, improving over existing results which show a "threshold effect". Evaluated on finetuned features, we find that DARE compares favorably to prior methods, consistently achieving equal or better performance.