 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation Regularization for Spectral Pruning
Paper and Code
Dec 26, 2019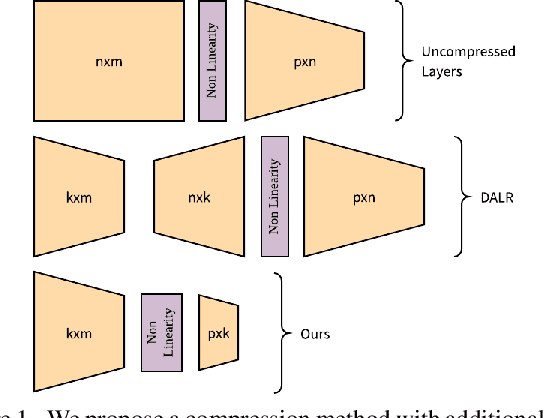
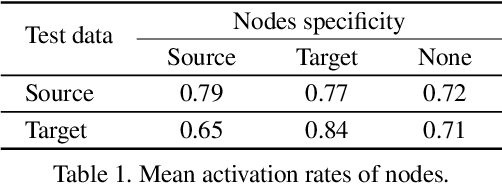
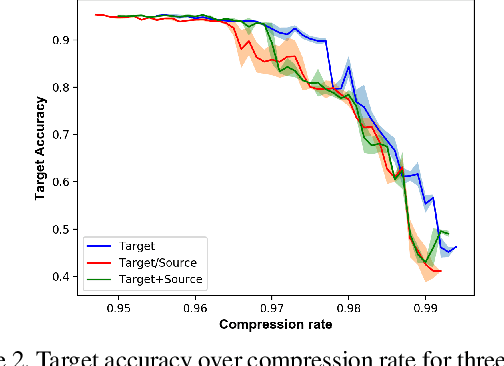
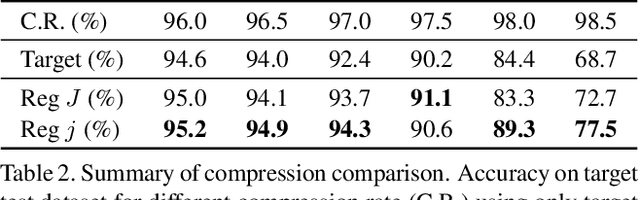
Deep Neural Networks (DNNs) have recently been achieving state-of-the-art performance on a variety of computer vision related tasks. However, their computational cost limits their ability to be implemented in embedded systems with restricted resources or strict latency constraints. Model compression has therefore been an active field of research to overcome this issue. On the other hand, DNNs typically require massive amounts of labeled data to be trained. This represents a second limitation to their deployment. Domain Adaptation (DA) addresses this issue by allowing to transfer knowledge learned on one labeled source distribution to a target distribution, possibly unlabeled. In this paper, we investigate on possible improvements of compression methods in DA setting. We focus on a compression method that was previously developed in the context of a single data distribution and show that, with a careful choice of data to use during compression and additional regularization terms directly related to DA objectives, it is possible to improve compression results. We also show that our method outperforms an existing compression method studied in the DA setting by a large margin for high compression rates. Although our work is based on one specific compression method, we also outline some general guidelines for improving compression in DA setting.