 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Simultaneous Speech Translation need Simultaneous Models?
Paper and Code


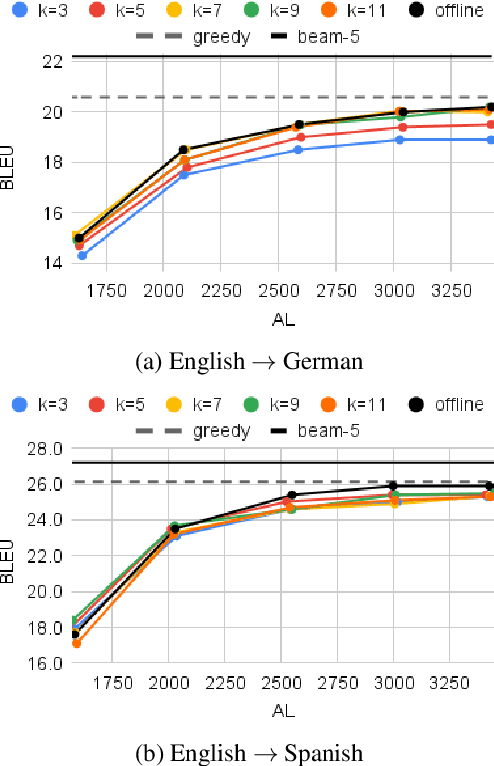

In simultaneous speech translation (SimulST), finding the best trade-off between high translation quality and low latency is a challenging task. To meet the latency constraints posed by the different application scenarios, multiple dedicated SimulST models are usually trained and maintained, generating high computational costs. In this paper, motivated by the increased social and environmental impact caused by these costs, we investigate whether a single model trained offline can serve not only the offline but also the simultaneous task without the need for any additional training or adaptation. Experiments on en->{de, es} indicate that, aside from facilitating the adoption of well-established offline techniques and architectures without affecting latency, the offline solution achieves similar or better translation quality compared to the same model trained in simultaneous settings, as well as being competitive with the SimulST state of the art.