 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Monocular Depth Estimation Provide Better Pre-training than Classification for Semantic Segmentation?
Paper and Code
Mar 29, 2022
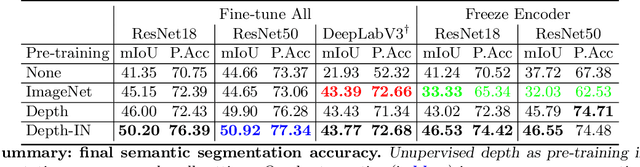
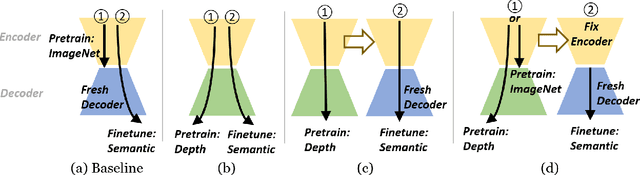
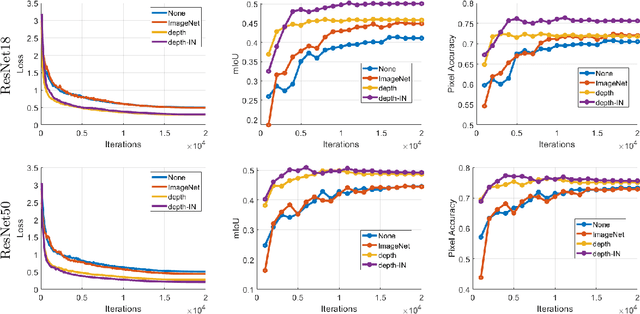
Training a deep neural network for semantic segmentation is labor-intensive, so it is common to pre-train it for a different task, and then fine-tune it with a small annotated dataset. State-of-the-art methods use image classification for pre-training, which introduces uncontrolled biases. We test the hypothesis that depth estimation from unlabeled videos may provide better pre-training. Despite the absence of any semantic information, we argue that estimating scene geometry is closer to the task of semantic segmentation than classifying whole images into semantic classes. Since analytical validation is intractable, we test the hypothesis empirically by introducing a pre-training scheme that yields an improvement of 5.7% mIoU and 4.1% pixel accuracy over classification-based pre-training. While annotation is not needed for pre-training, it is needed for testing the hypothesis. We use the KITTI (outdoor) and NYU-V2 (indoor) benchmarks to that end, and provide an extensive discussion of the benefits and limitations of the proposed scheme in relation to existing unsupervised, self-supervised, and semi-supervised pre-training protocols.